Wydajność obliczeń
Wprowadzenie¶
Dla danego programu zazwyczaj interesuje nas jego szybkość, rozumiana jako czas wykonania wyrażony np. w sekundach. Bardziej szczegółową miarą jaką możemy zastosować jest liczba cykli procesora, która odpowiada temu w jaki sposób pracuje CPU (patrz procesor > taktowanie). Może ona być dużo bardziej praktyczna w przypadku pomiaru wydajności małych fragmentów kodu obliczeniowego, gdyż w jednej sekundzie procesor wykonuje kilka miliardów cykli. Z kolei w odniesieniu do ilości wykonanej pracy możemy skupić się np. na tym jaka liczba operacji arytmetycznych została wykonana czy – patrząc bardziej niskopoziomowo – jaka jest liczba instrukcji asemblerowych, którą wykonał procesor.
Mówiąc o wydajności obliczeń, zwykle skupiamy się na tym jaka jest ich efektywność, czyli stosunek ilości wykonanych obliczeń do czasu potrzebnego na ich zrealizowanie. Istnieje kilka miar używanych do charakteryzacji tak rozumianej wydajności:
- FLOPS – liczba operacji zmiennoprzecinkowych na sekundę (floating-point operations per second);
- MIPS lub IPS – liczba (miliona) instrukcji na sekundę (instructions per second);
- CPI lub IPC – liczba cykli na instrukcję (cycles per instruction) lub jej odwrotność (instructions per cycle).
Każda z tych miar pozwala uchwycić inny aspekt, który może być mniej lub bardziej adekwatny do oceny wydajności danego programu lub jego fragmentu. Powyższe wskaźniki mogą również służyć do opisu wydajności układów obliczeniowych (tj. procesorów, akceleratorów) oraz określenia jaka jest moc obliczeniowa komputera.
Szczegóły¶
Mierzenie różnych wskaźników efektywności obliczeń jest jednym z elementów analizy wydajności. Może być szczególnie przydatne w procesie optymalizacji do porównywania ze sobą wydajności kolejnych wersji danego programu. Takie miary jak FLOPS, CPI, MIPS możemy odnieść do:
- wydajności konkretnego programu lub jego fragmentu (np. danej funkcji, pętli),
- zdolności obliczeniowych danego urządzenia (np. procesora) lub całego komputera.
W tym drugim przypadku chodzi o określenie maksymalnych wartości jakie dany sprzęt może uzyskać. Pozwala to na orientacyjne porównywanie między sobą różnych układów obliczeniowych oraz systemów komputerowych. Przykładem może być teoretyczna moc obliczeniowa superkomputerów, która zazwyczaj jest wyrażana we FLOPS-ach. Praktyczną wydajność testuje się również poprzez benchmarki.
Inne spojrzenia na wydajność
Innym aspektem dot. wydajności obliczeń jest wydajność energetyczna (tzw. performance per watt). Skupiamy się wtedy na koszcie energetycznym przeprowadzenia danych obliczeń.
Osobnym zagadnieniem jest to czy dane obliczenia są potrzebne czy nie. Możemy mieć sytuację w której z perspektywy wykorzystania zasobów obliczeniowych dany program jest bardzo efektywny. Jednakże może się okazać, że wybierając inną metodę obliczeniową będziemy w stanie istotnie zmniejszyć liczbę operacji i w dużo krótszym czasie uzyskać rozwiązanie danego problemu. W tej sferze przydatne może być myślenie kategoriami złożoności obliczeniowej.
FLOPS¶
FLOPS (floating-point operations per second) to miara wydajności obliczeń, mierzona jako średnia liczba operacji zmiennoprzecinkowych wykonywanych przez komputer w jednej sekundzie. Operacje zmiennoprzecinkowe to takie operacje jak np. dodawanie, mnożenie, pierwiastkowanie, które są wykonywane na zmiennych reprezentujących liczby rzeczywiste. Przykładowo, dla języka C będą to operacje wykonywane na zmiennych typu float (pojedyncza precyzja) lub double (podwójna precyzja). Pojedynczą operację zmiennoprzecinkową będziemy oznaczać jako FLOP, stąd 1 FLOPS = 1 FLOP/s.
Przedrostki FLOPS
Jednostkę często stosuje się z przedrostkami, np. GFLOPS, TFLOPS, PFLOPS to odpowiednio giga-, tera-, peta-, czyli , , FLOPS.
Konwencja oznaczania jednostek
W różnych materiałach można spotkać różne konwencje zapisu:
- FLOP, Flop, flop – są stosowane do oznaczenia operacji zmiennoprzecinkowej,
- wskaźnik FLOPS jest także oznaczany jako FLOP/s, Flop/s, flop/s.
Warto zwrócić uwagę, że FLOPs zazwyczaj jest używane jako liczba mnoga od FLOP. Z kolei flops może zarówno odnosić się do flop/s jak i do liczby mnogiej od flop.
FLOPS pomija inne instrukcje typu ładowanie danych do pamięci, zmiana przepływu sterowania (skok) czy arytmetyka całkowitoliczbowa. Przykładem tej ostatniej może być inkrementacja zmiennej sterującej pętlą albo obliczanie indeksów w celu odwołania się do tablicy przechowującej dane. W kontekście obliczeń naukowych i inżynieryjnych, wskaźnik FLOPS stosunkowo dobrze oddaje możliwości obliczeniowe danego komputera. Jest tak dlatego, że większość istotnych obliczeń dla wielu problemów oraz stosowane metody numeryczne sprowadzają się właśnie do wykonania określonej liczby operacji na liczbach zmiennoprzecinkowych. Przykładowo, aby obliczyć iloczyn skalarny wektorów o 3 współrzędnych, potrzebujemy 5 operacji: 3 mnożenia oraz 2 dodawania.
Aby ustalić wskaźnik FLOPS dla danego programu czy pojedynczej funkcji, naturalnie potrzebujemy zmierzyć czas jego działania oraz ustalić (przybliżoną) liczbę FLOP-ów (liczbę operacji zmiennoprzecinkowych) jaka została wykonana. Tę drugą wartość możemy oszacować sami na podstawie kodu źródłowego, chociaż dla bardziej złożonych programów może być to nieco żmudne. Można spotkać się z różnymi konwencjami odnośnie tego czy w liczbie FLOP-ów uwzględniamy wyłącznie dodawania i mnożenia, czy również porównania zmiennych. Osobną kwestią jest to w jaki sposób traktować bardziej złożone i czasochłonne operacje jak pierwiastkowanie.
Porada – mierzenie FLOPS
Do automatycznego pomiaru pomocne mogą być narzędzia do analizy wydajności. Bardzo często, pośród różnych wskaźników, zliczają one ilość wykonanych przez procesor operacji różnego typu i podają wskaźnik FLOPS.
⚠️ Względność miary¶
Kiedy mówimy o wydajności FLOPS, należy doprecyzować o jakich operacjach zmiennoprzecinkowych mówimy. Możemy bowiem wykonywać obliczenia w różnej precyzji. Klasyczny podział to FP32 (pojedyncza precyzja) oraz FP64 (podwójna precyzja)1. Współcześnie, szczególnie w kontekście obliczeń dot. sieci neuronowych, popularna również jest mniejsza precyzja FP16, która wymaga tylko 16 bitów.
Zazwyczaj zmniejszenie precyzji obliczeń o połowę powoduje dwukrotny wzrost wydajności FLOPS. Jest tak z powodu wektoryzacji – gdy pojedyncza zmienna zajmuje dwa razy mniej pamięci, wtedy w rejestrze wektorowym możemy zmieścić dwa razy więcej zmiennych. Oznacza to że pojedyncza instrukcja wektorowa jednocześnie wykona dwukrotnie większą liczbę FLOP-ów. Fakt że różna precyzja daje różną wydajność jest czasem uwzględniony w specyfikacjach producentów. Przykładem może być specyfikacja NVIDIA GPU A100.
Porada
Jeśli w jakimkolwiek miejscu prezentowana jest wydajność we FLOPS, warto zweryfikować jakiej precyzji dotyczy. Pozwoli to uniknąć błędnej interpretacji wyników, szczególnie jeśli porównujemy wyniki z różnych źródeł.
Moc obliczeniowa¶
Współcześnie bardzo często używa się miary FLOPS do określenia jaka jest teoretyczna maksymalna wydajność danego układu obliczeniowego lub całego systemu komputerowego (czasem określana jako Peak FLOPS). Taka wydajność jest nazywana mocą obliczeniową i zwykle odnosi się do obliczeń podwójnej precyzji (FP64). Jej podawanie jest szczególnie popularne w świecie superkomputerów (HPC), jako miara służąca do porównywania zdolności obliczeniowych różnych komputerów.
Najbardziej wydajny komputer na świecie
W listopadzie 2023 roku największą teoretyczną moc obliczeniową posiadał superkomputer Frontier – wyniosła ona niespełna 1.7 EFLOPS (eksa-flops, czyli FLOPS) dla obliczeń FP64. Przekroczenie granicy eksa-FLOPS było ważnym wydarzeniem, oczekiwanym od kilku lat. To właśnie do tej jednostki nawiązuje pojęcie obliczenia eksaskalowe (exascale computing), popularne obecnie w świecie HPC.
Teoretyczna moc procesora (CPU) jest wyliczana w następujący sposób. Podstawą jest określenie jaka jest moc pojedynczego rdzenia. W tym celu:
- Określa się ile maksymalnie FLOP-ów może zostać wykonanych w jednym cyklu. Pod uwagę brana jest ilość jednostek wykonawczych, typ wykonywanej instrukcji oraz wektoryzacja (patrz CPU > architektura rdzenia).
- Otrzymaną wartość mnoży się przez ilość cykli wykonywanych w jednej sekundzie, czyli przez częstotliwość taktowania procesora.

Przykład obliczania wydajności rdzenia – podstawowe operacje
Rozważmy procesor, który posiada dwie jednostki wykonawcze pozwalające na wykonywanie operacji zmiennoprzecinkowych. Każda z nich może w jednym cyklu ukończyć2 np. 1 instrukcję dodawania lub 1 instrukcję mnożenia, czyli zrealizować 1 FLOP. Przyjmując taktowanie 2 GHz otrzymujemy:
| wydajność rdzenia (bez wektoryzacji) |
= | 2 GHz x (2 x 1 FLOP / cykl) = 4 GFLOPS |
Kontynuacja przykładu – uwzględnienie wektoryzacji
Aby uzyskać większą wydajność obliczeń stosowana jest wektoryzacja. Pozwala ona na wykonywanie tej samej operacji na kilku liczbach naraz. Przyjmijmy, że nasz procesor posiada 256-bitowe rejestry wektorowe, co pozwala na zmieszczenie w nich czterech liczb podwójnej precyzji (FP64). Zakładając, że obydwie jednostki wykonawcze potrafią wykonywać instrukcje wektorowe, otrzymujemy:
| wydajność rdzenia (wektoryzacja, 256-bit) |
= | 2 GHz x (2 x 4 FLOP / cykl) = 16 GFLOPS |
Gdyby procesor posiadał rozszerzenie AVX-512, czyli możliwość wektoryzacji na rejestrach 512-bitowych, jego teoretyczna wydajność uległaby podwojeniu (z zastrzeżeniem opisanym w sekcji taktowanie a instrukcje wektorowe). Wydajność rdzenia mogłaby wtedy sięgnąć 32 GFLOPS.
Kontynuacja przykładu – różne precyzje
Odwołując się do poprzedniego przykładu, rozważmy operacje FLOP różnej precyzji. W rejestrze 256-bitowym mieszczą się odpowiednio: 4 liczby FP64, 8 liczb FP32, 16 liczb FP16. Przekłada się to odpowiednio na wydajność:
| wydajność dla FP64 | = | 2 GHz x (2 x 4 FLOP / cykl) = 16 GFLOPS |
| wydajność dla FP32 | = | 2 GHz x (2 x 8 FLOP / cykl) = 32 GFLOPS |
| wydajność dla FP16 | = | 2 GHz x (2 x 16 FLOP / cykl) = 64 GFLOPS |
Kontynuacja przykładu – uwzględnienie instrukcji FMA
Współczesne procesory dla optymalizacji typowych obliczeń posiadają instrukcje FMA (fused multiply-add). Reprezentują one równoczesne wykonanie dodawania i mnożenia według schematu: . Z tego względu wykonanie jednej instrukcji FMA jest liczone jako 2 FLOP-y, co daje dwukrotne przyspieszenie. W połączeniu z 256-bitową wektoryzacją, tj. jednoczesnym przetwarzaniu 4 zmiennych FP64, pojedyncza jednostka wykonawcza może w jednym cyklu wykonać 8 FLOP-ów. Przy dwóch jednostkach wykonawczych otrzymujemy:
| wydajność rdzenia (FMA, wektoryzacja, 256-bit) |
= | 2 GHz x (2 x 8 FLOP / cykl) = 32 GFLOPS |
Mając ustaloną maksymalną wydajność pojedynczego rdzenia bardzo łatwo policzyć wydajność procesora czy wydajność całego komputera. Jest ona obliczana po prostu jako iloczyn liczby rdzeni oraz mocy pojedynczego rdzenia.

Moc obliczeniowa superkomputera Ares
W przypadku superkomputera Ares działającego w ACK Cyfronet AGH, teoretyczna moc obliczeniowa komputera (bez udziału GPU) została obliczona w następujący sposób.
| wydajność rdzenia | = | 2.9 GHz x 32 FLOP / cykl = 92.8 GFLOPS |
| liczba rdzeni | = | 788 węzłów x 48 rdzeni / węzeł = 37 824 rdzeni |
| moc obliczeniowa Aresa | = | 37 824 rdzeni x 92.8 GFLOPS = 3.51 PFLOPS |
Wyjaśnienie:
- Superkomputer Ares jest wyposażony w procesory Intel Xeon Platinum 8268:
- pojedynczy procesor posiada 24 rdzenie,
- jego bazowe taktowanie wynosi 2.90 GHz.
- Każdy rdzeń tego procesora jest w stanie wykonywać jednocześnie 2 operacje FMA i posiada 512-bitowe rejestry. Przekłada się to na możliwość wykonania 2 x 2 x 8 = 32 FLOP-ów w jednym cyklu (dwie operacje FMA, każda realizuje 2 FLOP, pojedynczy rejestr mieści 8 zmiennych typu FP64).
- Na każdym węźle obliczeniowym superkomputera znajdują się dwa procesory, gdyż każdy węzeł jest wyposażony w dwa sockety (gniazda procesora). W efekcie pojedynczy węzeł ma 2 x 24 = 48 rdzeni.
- Superkomputer posiada dwie partycje CPU: standardową z 532 węzłami oraz tzw. bigmem o 256 węzłach wyposażonych w dodatkową pamięć. W związku z tym całkowita liczba wynosi 788 węzłów.
Omówienie¶
Jak widać ze sposobu obliczania, teoretyczna moc odpowiada sytuacji, w której procesor cały czas wykonuje ten sam rodzaj najbardziej efektywnych instrukcji. Warto zwrócić uwagę na to, że w obliczeniach zostało przyjęte, że w każdym cyklu jest możliwe ukończenie jednej instrukcji. Wynika to z uwzględnienia przetwarzania potokowego i założenia, że w każdym cyklu jednostki wykonawcze rdzenia są obciążone. Odpowiada to nierealistycznemu scenariuszowi, w którym żadne dane nie są pobierane ani zapisywane do pamięci oraz nie są wykonywane żadne instrukcje sterujące.
wizualizacja procesu optymalizacji wydajności [źródło]
Mimo tego że teoretyczna moc jest raczej nieosiągalna, daje ona pewien punkt odniesienia. W procesie optymalizacji możemy starać się jak najbardziej do niej zbliżyć oraz zadawać sobie pytanie jakie czynniki powstrzymują program przed uzyskaniem większej wydajności. Sposób wyznaczania maksymalnej mocy odwołuje się do zrozumienia potencjalnych możliwości obliczeniowych danego komputera. Można zaadaptować go do określenia, jaką teoretyczną wydajność można uzyskać, biorąc pod uwagę specyfikę konkretnego programu. Przykładowo, jeśli nie korzystamy z FMA, wiemy, że maksymalna wydajność będzie odpowiednio mniejsza; podobnie w sytuacji gdy nie jest możliwa wektoryzacja.
Porada – dokładniejszy model wydajności
Teoretyczna moc pokazuje maksymalne możliwości obliczeniowe komputera, jednak pomija kwestie ograniczeń wynikających z dostępu do pamięci. Dokładniejsze spojrzenie na możliwą do uzyskania wydajność, z uwzględnieniem szybkości pamięci, oferuje model Roofline.
Taktowanie a instrukcje wektorowe¶
Rozważając maksymalną moc obliczeniową danego procesora, ⚠️ należy być ostrożnym w szacowaniu wpływu wektoryzacji na zwiększenie wydajności. W szczególności, skorzystanie z dwukrotnie większych instrukcji wektorowych nie zawsze przyniesie dwukrotną poprawę wydajności. Dotyczy to szczególnie tych sytuacji, gdy CPU pracuje z wyższym taktowaniem niż bazowe (czyli z tzw. max turbo frequency).
Wyjaśnienie – wpływ taktowania na wektoryzację
Problem wynika z tego, że przy korzystaniu z instrukcji wektorowych (AVX), szczególnie tych o długości 512-bitów (AVX-512), niektóre procesory muszą zmniejszyć swoją częstotliwość. Jako przykład może posłużyć taktowanie procesora Intel Xeon Platinum 8268. Jego maksymalna częstotliwość pracy wynosi odpowiednio:
- 3.5 GHz – bez wektoryzacji,
- 3.0 GHz – dla operacji AVX2,
- 2.6 GHz – dla operacji AVX-512.

Z dyskusji wynika, że tego typu ograniczenie dotyczy głównie starszych procesorów firmy Intel, a w nowszych generacjach takie spowolnienie powinno być mniej odczuwalne (zobacz np. wpis o AVX-512 na lwn.net z 2022 roku).
Więcej informacji:
- Mechanism to Mitigate AVX-Induced Frequency Reduction (2018) - artykuł naukowy opisujący przypadki zmniejszenia wydajności programów ze względu na korzystanie z AVX
- SIMD instructions lowering CPU frequency (Stack Overflow) (2019) - rzeczowe wyjaśnienia i komentarze, z propozycjami jakich opcji kompilacji używać
- Intel® Xeon® Processor Scalable Family Specification Update (2023) – dokumentacja procesorów Intel Xeon Scalable, zawierająca tabelę z "Turbo Frequencies" dla różnych przypadków korzystania z AVX
Benchmarki¶
Opisana powyżej moc obliczeniowa pozwala określić jaka jest teoretyczna maksymalna wydajność danej maszyny (mierzona we FLOPS). W praktyce taka wartość jest raczej nieosiągalna. Z tego względu pożądane jest określenie jaka jest rzeczywista wydajność danego komputera w różnych zastosowaniach. W tym celu stosuje się tzw. benchmarki.
Benchmark to program służący do określania wydajności pojedynczego komponentu (np. procesora, karty GPU, dysku, pamięci, sieci) lub komputera jako całości, w kontekście konkretnego zadania, np. mnożenia macierzy czy kompresji danych. Wyniki danego benchmarku mogą posłużyć do porównania ze sobą wydajności różnych komputerów i różnych konfiguracji sprzętowych.
Benchmarki – wydajność oprogramowania i kompilacji
Benchmarki korzystające z zewnętrznych bibliotek lub programów, mogą być wykorzystane do oceny wydajności różnych wersji, kompilacji lub implementacji takiego oprogramowania. Przykładowo, dla benchmarku zrównoleglonego przy użyciu MPI, można przetestować różne implementacje tej biblioteki. Można także porównać wydajność nowszej wersji względem starszej.
W przypadku samodzielnej kompilacji benchmarku możemy również testować wpływ wybranego kompilatora oraz opcji kompilacji na uzyskaną wydajność.
Typowe benchmarki, to programy napisane stricte w celu testowania wydajności. Zwykle skupiają się na jednym rodzaju obliczeń albo testują konkretny aspekt wydajności komputera. Ich kod zazwyczaj jest zoptymalizowany. Benchmarki są też tworzone z myślą o konkretnym modelu programistycznym. Przykładowo mogą mierzyć wydajność CPU lub GPU; mogą realizować obliczenia sekwencyjne, zrównoleglone na wiele rdzeni albo rozproszone na wiele komputerów. Oprócz typowych benchmarków tak naprawdę dowolny program obliczeniowy może posłużyć jako miara wydajności komputera. Więcej w sekcji aplikacja jako benchmark.
Przykłady typowych benchmarków
Przykładem benchmarków służących do określenia wydajności obliczeniowej są HPL i HPCG. Są one popularne w środowisku superkomputerów.
Innym przykładem może być zestaw OSU Micro-Benchmarks, który służy do pomiaru różnych aspektów wydajności komunikacji sieciowej między węzłami klastra obliczeniowego, jak również szybkości transferu danych wewnątrz pojedynczego węzła.
W kontekście danego benchmarku, w odróżnieniu od teoretycznej wydajności (peak performance), możemy mówić o tym jaka jest wydajność zmierzona (measured performance, sustained performance). W zależności od tego jakie zadanie wykonuje dany benchmark, jego wynik może być przedstawiony w różnych jednostkach, np. we FLOPS dla obliczeń numerycznych.
Przykłady jednostek wynikowych dla benchmarków
- wynik punktowy (score) – charakterystyczny dla danego benchmarku,
- liczba FLOPS – dla obliczeń numerycznych,
- czas wykonania – dla dowolnego programu i konkretnie zdefiniowanego problemu,
- liczba ns/day – dla dynamiki molekularnej, która oznacza liczbę zrealizowanych nanosekund symulacji, w przeliczeniu na jeden dzień prowadzenia obliczeń,
- liczba obrazów/s – dla sieci neuronowych przetwarzających obrazy,
- szybkość transferu (MB/s) – dla pomiaru szybkości pamięci, dysku albo komunikacji po sieci (zobacz szybkość dostępu do danych).
Benchmarki dotyczące innych aspektów
Oprócz wydajności, benchmarki mogą również oceniać jakość danego oprogramowania lub metody obliczeniowej. Przykładowo:
- W uczeniu maszynowym, w zadaniach dot. klasyfikacji sprawdza się dokładność danego modelu (accuracy), czyli to jak dużo odpowiedzi modelu było poprawnych. Dla modeli generatywnych (LLM) określenie poprawności odpowiedzi jest trudniejsze, ale również są opracowane benchmarki badające ich jakość w stosunku do różnych zadań (zobacz np. Open LLM Leaderboard).
- W obliczeniach kwantowo-chemicznych można porównywać ze sobą różne metody obliczeniowe na tym samym układzie (np. cząsteczce). Przykładowo można porównać ze sobą wartości energii uzyskane przy użyciu dwóch funkcjonałów gęstości elektronowej. Wartość która będzie bliższa energii oczekiwanej, wskaże funkcjonał bardziej dokładny dla tego typu układu.
HPL (LINPACK)¶
Benchmark LINPACK oraz HPL (High Performance Linpack) to benchmarki, które na przestrzeni lat stały się standardem pomiaru wydajności obliczeń numerycznych, popularnym szczególnie w środowisku superkomputerów (HPC). Mierzą szybkość rozwiązywania gęstego układu równań liniowych. Taki układ jest zadany w postaci dużej macierzy liczb rzeczywistych, a algorytm służący do jego rozwiązania opiera się o faktoryzację LU. To zadanie odpowiada obliczeniom często spotykanym w problemach naukowych i inżynieryjnych. Wynik benchmarku jest podawany jako liczba FLOPS.
Benchmark LINPACK to pierwotna wersja benchmarku (początki sięgają 1979 roku), jej nazwa pochodzi od biblioteki LINPACK, która współcześnie nie jest już stosowana (została zastąpiona przez LAPACK). HPL to wysoce zoptymalizowana równoległa implementacja benchmarku LINPACK, przeznaczona do uruchamiania w środowisku rozproszonym (wymaga MPI). Potocznie obydwie nazwy stosuje się wymiennie, mając na myśli równoległą implementację.
Cechą charakterystyczną tego benchmarku jest to że rozważany problem jest dobrze skalowalny, dzięki czemu oddaje on zdolność obliczeniową systemu jako całości. Wydajność uzyskana w HPL jest wykorzystywana do porównywania największych superkomputerów na świecie. To właśnie według niej tworzony jest ranking superkomputerów – lista TOP500. Warto dodać, że nie istnieje jedna implementacja HPL. Każdy producent sprzętu może dostarczyć własną implementację, zoptymalizowaną pod swoje układy obliczeniowe, której celem jest uzyskanie jak najlepszej wydajności na danym superkomputerze.
Optymalizacja wyników HPL pod kątem TOP500
Warto mieć na uwadze, że ośrodki HPC dokładają starań do tego by uzyskać jak najlepszy wynik w HPL. Przejawem tego może być to, że benchmark wykonywany na potrzeby zgłoszenia do listy TOP500, może odbywać się na nieco innej konfiguracji systemu niż ta, która jest później stosowana na co dzień. Przykładowo dopuszcza się zwiększone częstotliwości taktowania i w konsekwencji, wyższe zużycie prądu.
HPCG¶
Benchmark HPCG (High Performance Conjugate Gradients) powstał jako uzupełnienie HPL, aby mierzyć wydajność komputerów na bardziej zróżnicowanym zbiorze zadań. Jest on oparty o taki rodzaj obliczeń, który posiada mniej regularny schemat dostępu do danych niż HPL. W efekcie, jest on dużo bardziej podatny na opóźnienia wynikające z dostępu do pamięci i komunikacji sieciowej (patrz szybkość dostępu do danych).
HPCG jest reprezentatywny dla dużej liczby aplikacji używanych w badaniach naukowych. Operacje w nim zawarte to m.in.:
- SpMV, czyli mnożenie macierzy rzadkich przez wektor (w HPL macierze były gęste),
- metoda Gaussa-Seidla,
- czy zawarty w nazwie algorytm sprzężonych gradientów, który jest wykorzystywany m.in. w chemii obliczeniowej do uzyskiwania bardzo dokładnych wartości energii.
Na podstawie tego benchmarku, obok listy TOP500 (opartej o HPL), tworzony jest ranking HPCG. W porównaniu z HPL, benchmark HPCG daje znacznie niższe wartości FLOPS. Również kolejność superkomputerów o najwyższej mocy może być różna dla tych testów.
Zestawienie mocy obliczeniowej z wydajnością HPL i HPCG
Dla zobrazowania różnicy w wynikach, rozważmy ranking superkomputerów z listopada 2023 (patrz TOP500 – listopad 2023 oraz HPCG – listopad 2023):
- zajmujący 1. miejsce w TOP500 Frontier znalazł się na 2. miejscu w HPCG,
- superkomputer Fugaku, który zajął 4. miejsce na TOP500, jest na 1. miejscu wg HPCG.
| Superkomputer | Peak FLOPS | HPL | HPCG |
|---|---|---|---|
| Frontier | 1 679,82 | 1 194,00 | 14,05 |
| Fugaku | 537,21 | 442.01 | 16,00 |
wyniki w peta-FLOPS ( FLOPS)
Aplikacja jako benchmark¶
Typowe benchmarki, jak HPL czy HPCG, dostarczają informacji o tym jaką wydajność uzyskuje pewien kod obliczeniowy. Jednakże w stosunku do używanych przez nas aplikacji, zazwyczaj interesuje nas jaka jest wydajność konkretnego oprogramowania. Nic nie stoi na przeszkodzie, by program, który stworzono w innym celu niż testowanie wydajności, został użyty jako benchmark dla zadań określonego typu. Aby to zrobić, należy ustalić konkretny test (parametry, dane wejściowe) na którym będzie uruchamaniana wybrana aplikacja.
Zastosowania
Jako przykład benchmarku może posłużyć wykorzystanie aplikacji GROMACS do wykonania dynamiki molekularnej konkretnego białka przy zadanych parametrach. Tak ustalony test może mieć wiele zastosowań:
- porównanie wydajności tej samej wersji GROMACS na dwóch różnych komputerach,
- test wydajności komputera po wymianie sprzętu,
- porównanie wydajności w zależności od tego czy obliczenia są wykonywane na CPU czy na GPU,
- porównanie wydajności dwóch wersji GROMACS-a, by wychwycić ewentualną poprawę lub pogorszenie wydajności między wersjami (deweloperzy zwykle prowadzą tego typu testy, by wychwycić niepożądane spadki wydajności oprogramowania po aktualizacji kodu),
- porównanie wydajności różnych kompilacji tej samej wersji GROMACS-a,
- porównanie wydajności tej samej wersji GROMACS-a, w zależności od użytych bibliotek zewnętrznych (np. MPI),
- porównanie wydajności obliczeń w zależności od konfiguracji wykonania aplikacji (np. ustawienie przypinania wątków do rdzeni, czy zdefiniowanie zmiennych środowiskowych sterujących zachowaniem programu),
- testy skalowalności, tj. obserwacja zmiany wydajności przy zwiększaniu zasobów obliczeniowych (liczby rdzeni oraz węzłów).
Wymienione powyżej zastosowania można oczywiście odnieść do dowolnej aplikacji. Jako miarę wydajności zawsze można wykorzystać czas wykonania ustalonego testu. Dany program może również zwracać jakąś wartość charakterystyczną (np. ns/day dla GROMACS). Wyniki uzyskane dla ustalonego testu są specyficzne dla tego konkretnego zadania (np. danego białka). Mogą one jednak pozwolić na lepsze wnioskowanie o zachowaniu danej aplikacji niż porównywanie ze sobą wyników benchmarków niezwiązanych z aplikacją.
Porada – charakteryzacja wydajności aplikacji
Do odpowiedniej charakteryzacji wydajności aplikacji na danej maszynie, należy wybrać przykład reprezentatywny dla interesującej nas grupy problemów obliczeniowych lub przygotować zbiór kilku testów, sprawdzających efektywność obliczeń w kilku przypadkach.
Na końcu warto zauważyć, że opisane w tej sekcji podejście dotyczy nie tylko gotowych aplikacji (takich jak np. GROMACS), ale ma również zastosowanie do własnego kodu obliczeniowego. Dobrą praktyką jest testowanie wydajności swojego kodu na zadaniach wymagających relatywnie mało zasobów obliczeniowych (tj. mniej węzłów, krótszy czas), zanim uruchomimy właściwe obliczenia. Podstawową miarą wydajności dla takiego testu jest całościowy czas ukończenia danego zadania. Możemy również:
- zdecydować się na bardziej dokładną ocenę wydajności przy użyciu profilerów (patrz dział Analiza wydajności),
- ustalić własną metrykę oceny wydajności,
- wprowadzić do kodu źródłowego pomiar czasu działania wybranych części naszej aplikacji.
Podsumowanie¶
Benchmarki służą jako orientacyjne narzędzie do określania realnej wydajności komputerów jako całości, ich poszczególnych komponentów lub danego oprogramowania. Stosując je należy pamiętać o kilku aspektach:
- Nie istnieje jeden test, którym można zbadać "absolutną" moc obliczeniową komputera. Nie ma bowiem jednej wartości, która by ją opisywała.
- Wydajność uzyskana przy pomocy jakiegokolwiek benchmarku jest pojęciem względnym i trudno na jej podstawie określić czy dany komputer jest "lepszy", czy "gorszy" niż inny komputer. Wyniki jednego benchmarku, mogą nie przystawać do wyników innego.
- Do wyciągania wniosków na podstawie benchmarku, konieczne jest zapoznanie się z jego charakterystyką: jaki rodzaj operacji wykonuje, jakiemu problemowi obliczeniowemu odpowiada, jakie zasoby wykorzystuje.
- Wynik danego benchmarku może być dobrym punktem odniesienia dla tych aplikacji, które wykonują podobne operacje. Przykładowo, wydajność faktoryzacji LU macierzy można porównywać z osiągami jakie uzyskuje HPL.
W zależności od tego w jakim celu mierzymy wydajność, należy wybrać odpowiedni benchmark lub zestaw benchmarków.
- Ogólną wydajność komputera przeznaczonego do wielu zastosowań można próbować wyrazić poprzez zbiór wyników wielu różnorodnych benchmarków, uwzględniając w tym najczęściej używane, praktyczne aplikacje.
- Konkretny aspekt wydajności należy mierzyć przy użyciu benchmarków, które w istotnym stopniu go wykorzystują. Przykładowo, do porównania wydajności wielu rdzeni, benchmark musi być dobrze zrównoleglony; do oceny wydajności komunikacji sieciowej, aplikacja powinna wymieniać dużo danych między procesami.
- Dla określonej dziedziny obliczeń należy wybrać reprezentatywny przykład, którego wydajność przekłada się na wydajność typowych obliczeń w tej dziedzinie.
Cykle i instrukcje – CPI/IPC¶
Analizując działanie programu z perspektywy CPU, możemy badać następujące wartości:
- ile cykli procesora zajęło wykonanie danych obliczeń,
- ile instrukcji maszynowych zostało wykonanych.
Zestawienie ze sobą tych dwóch wartości pozwala ocenić stopień wykorzystania możliwości obliczeniowych procesora. W tym celu stosuje się wskaźnik CPI (cycles per instruction, nazywany również clocks per instruction) – ile cykli zegara potrzeba średnio, aby rdzeń procesora ukończył wykonanie jednej instrukcji. Naturalnie, mniejsza wartość CPI oznacza lepsze wykorzystanie CPU. Czasami wygodniej jest mówić o odwrotnej wartości – średniej liczbie instrukcji wykonanych w jednym cyklu; jest to wskaźnik IPC (instructions per cycle lub instructions per clock).
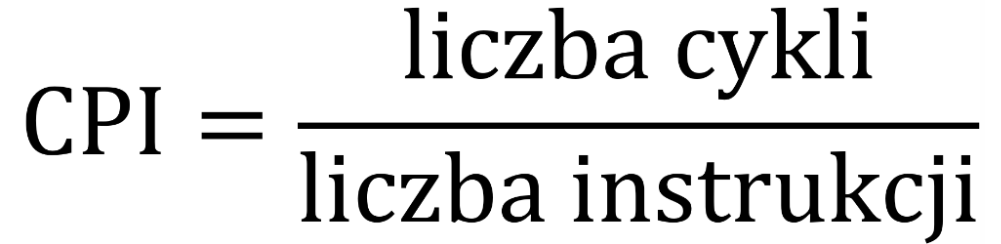
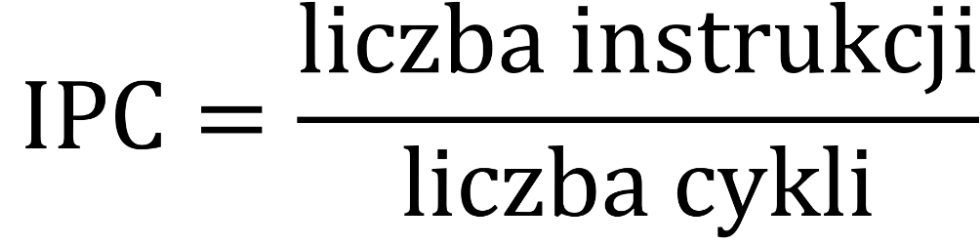
Równoległość przetwarzania instrukcji przez CPU
Każda instrukcja maszynowa jest przetwarzana przez procesor przez kilka cykli – jest to tzw. opóźnienie (instruction latency). Jednakże we współczesnych procesorach, dzięki przetwarzaniu potokowemu oraz superskalarności (patrz CPU > jednostki wykonawcze), pojedynczy rdzeń jest w stanie równocześnie przetwarzać wiele instrukcji. Ten mechanizm jest określany jako równoległość na poziomie instrukcji (instruction-level parallelism). Dzięki temu możliwe jest uzyskanie wartości CPI mniejszych niż 1 cykl / instrukcje. Przykładowo jeśli procesor ma 4 jednostki wykonawcze, możliwe jest uzyskanie CPI = 0.25 (czyli IPC = 4).
Dla konkretnego programu, wskaźniki CPI oraz IPC oddają stopień równoległości obliczeń na poziomie pojedynczego rdzenia. Im niższa wartość CPI (czyli wyższa wartość IPC), tym więcej operacji jest wykonywanych jednocześnie. CPI można też traktować jako średni czas przetwarzania instrukcji. Jego zestawienie z opóźnieniem pojedynczej instrukcji obrazuje, w jakim stopniu mechanizmy procesora do równoległego przetwarzania instrukcji zdołały zniwelować to opóźnienie.
CPI jako parametr wydajności procesora
Parametr CPI może być wykorzystany do opisu wydajności procesora – jako minimalna wartość, jaka może zostać uzyskana. Ten parametr określa się czasem jako przepustowość (throughput). Stosuje się go w kontekście konkretnej instrukcji, gdyż dla różnych instrukcji możliwa do uzyskania wartość CPI może być inna. Przykład: specyfikacja instrukcji wektorowych dla procesorów Intel.
Optymalizacja¶
W procesie optymalizacji kodu, wskaźnik CPI (lub odpowiednio IPC) może pełnić bardzo ważną rolę. Pozwala on na zlokalizowanie miejsc w kodzie, w których równoległość na poziomie instrukcji nie jest satysfakcjonująca. Poprawa takich miejsc może znacznie zwiększyć wydajność obliczeń na pojedynczym rdzeniu. Fragmenty kodu w których CPI jest duże (np. powyżej 2 cykli / instrukcję) to potencjalne miejsca, gdzie można uzyskać przyspieszenie.
Porada
Dla kodu typowo obliczeniowego pożądane jest aby osiągnąć CPI < 1.
Wskaźnik CPI najlepiej odnosić do pracy pojedynczego rdzenia oraz do małego fragmentu kodu (np. funkcji lub pętli). W przypadku podawania CPI dla większych fragmentów programu, szczególnie takich które łączą obliczenia o różnym charakterze, mamy do czynienia z pewnego rodzaju średnią CPI mniejszych fragmentów (nie jest to średnia arytmetyczna!). Taka ogólna wartość może dać jakiś ogląd na wydajność, ale ciężko na jej podstawie ustalić, w którym miejscu jest potencjał na poprawę.
Pomiary dla większej liczby rdzeni
W przypadku raportowania czasu działania, liczby cykli procesora oraz liczby instrukcji dla wielu CPU, narzędzia do analizy wydajności zwykle sumują wartości z poszczególnych rdzeni. Dzięki temu wartość CPI obliczona dla takiej sumy odpowiada pewnego rodzaju średniej CPI z kilku rdzeni. Gdyby liczba cykli różnych rdzeni nie była sumowana, wtedy wskaźnik CPI malałby wraz z uwzględnianiem większej liczby rdzeni.
W procesie optymalizacji, możemy badać CPI dla kolejnych wariantów programu. Nie można jednak skupiać się wyłącznie na poprawie CPI. Należy pamiętać, że równie ważna jest liczba instrukcji. Jeśli uda nam się znacznie zredukować liczbę instrukcji za cenę zwiększenia CPI, to taka poprawa może być opłacalna (taka sytuacja może mieć miejsce np. wtedy gdy uda nam się zwektoryzować część obliczeń). Wynika to z tego, że w ostatecznym rozrachunku ważne jest to czy sumaryczna liczba cykli potrzebnych na wykonanie tych instrukcji zostanie zredukowana.
Odczyt liczby cykli oraz instrukcji
Aby ustalić liczbę wykonanych cykli oraz instrukcji korzysta się z liczników sprzętowych (hardware counters), które znajdują się w procesorze. Do tego zadania bardzo pomocne są narzędzia do analizy wydajności, które potrafią zebrać te dane dla poszczególnych fragmentów programu. Niektóre z tych narzędzi automatycznie obliczają i prezentują wskaźnik CPI.
(M)IPS¶
IPS to wskaźnik wydajności, który mierzy ile średnio instrukcji maszynowych wykonał procesor w ciągu jednej sekundy (instructions per second). Ponieważ typowe wartości IPS dla procesorów znajdują się w przedziale milionów – bilionów, stosuje się miarę MIPS do oznaczenia milionów instrukcji na sekundę (million instructions per second). Można również spotkać się z podobnym określeniem MOPS (million operations per second). Jak łatwo zauważyć, wartość MIPS zależy od taktowania procesora, podobnie jak FLOPS.
MIPS był jednym z pierwszych wskaźników stosowanych do określenia mocy obliczeniowej komputerów i porównywania ich ze sobą. Jednakże z racji na to, że różne architektury komputerów posiadają różne zestawy instrukcji, a czas wykonywania instrukcji różni się między procesorami, wskaźnik ten nie był miarodajny. W związku w tym, skrót MIPS żartobliwie rozwijano jako "meaningless" lub "misleading indicator of processor speed". Współcześnie do opisu mocy obliczeniowej zwykle używa się miary FLOPS.
Miara MIPS może być przydatna do oceny wydajności komputera w kontekście konkretnego programu. Przykładowo, w odniesieniu do benchmarków Whetstone oraz Dhrystone mówi się odpowiednio o MWIPS (Millions of Whetstone Instructions Per Second) lub DMIPS (Dhrystone MIPS). Jej zastosowanie może być zasadne szczególnie w odniesieniu do programów wykonujących w większości działania całkowitoliczbowe, gdzie miara FLOPS będzie nieprzydatna.
IPS a IPC
IPS w dużym stopniu odpowiada wskaźnikowi IPC, przy czym ten drugi zwykle odnosimy od pojedynczego rzdenia. Łatwo zauważyć, że przy stałej częstotliwości taktowania3:
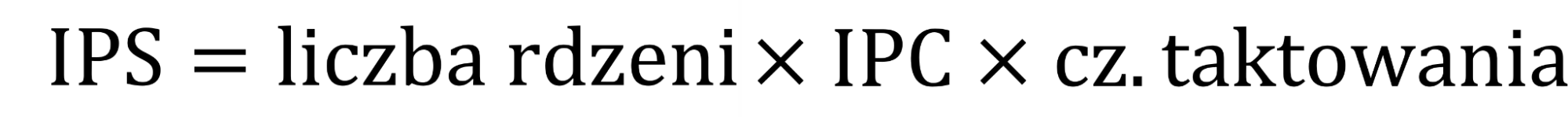
Uwzględnienie prędkości procesora w IPS sprawia, że ta miara bardziej nadaje się do określenia wydajności programu. Z kolei to że IPC jest niezależne od taktowania sprawia, że łatwiej odnieść tę wartość do równoległości obliczeń na poziomie pojedynczego rdzenia.
Linki¶
-
materiały dot. FLOPS i mocy obliczeniowej
- FLOPS: What is It and How It Impacts Your PC Performance (Lenovo) – zbiór pytań i odpowiedzi wyjaśniających różne aspekty dot. FLOPS
- Floating-Point Operations Per Second (WikiChip) - wyjaśnienie obliczania mocy obliczeniowej + wartości FLOPS dla różnych architektur CPU (brak informacji o najnowszych architekturach)
- Theoretical Peak Performance of a Computer (USC)4 – wyjaśnienie obliczania mocy obliczeniowej + przykład obliczeń dla komputera Fugaku
- Understanding Peak Floating-Point Performance Claims (Intel) – wyznaczanie mocy obliczeniowej dla innych układów niż CPU (DSP, GPU, FPGA)
- Counting flops (UARK)5 – liczba FLOP w kontekście złożoności algorytmów
-
materiały dot. benchmarków
- LINPACK FAQ - informacje dot. benchmarku LINPACK i listy TOP500
- High Performance LINPACK - objaśnienie czym jest HPL
- High Performance Conjugate Gradients - objaśnienie czym jest HPCG
-
materiały dot. CPI
- Clockticks per Instructions Retired (CPI) – opis metryki z dokumentacji profilera Intel VTune
-
materiały dot. MIPS
- What is million instructions per second? (TechTarget) – zwięzłe przedstawienie MIPS oraz czynników wpływających na wydajność procesora
- Timeline of instructions per second (Wikipedia) – wartości MIPS dla różnych procesorów na podstawie benchmarku Dhrystone
-
Oznaczenia FP32 oraz FP64 oznaczają odpowiednio liczby pojedynczej oraz podwójnej precyzji. Nazwa pochodzi od tego, że rozmiar takich liczb w pamięci komputera wynosi odpowiednio 32 oraz 64 bity (tj. 4 oraz 8 bajtów). ↩
-
Mówiąc o "ukończeniu instrukcji" odwołujemy się do mechanizmu przetwarzania potokowego (pipelining) w procesorze. Całkowite przetworzenie pojedynczej instrukcji zajmuje procesorowi więcej czasu niż 1 cykl, ale dzięki potokowości kilka instrukcji jest wykonywanych równolegle przez ten sam rdzeń (jest to tzw. instruction-level parallelism). W efekcie, w korzystnym przypadku, czas spędzony na danej instrukcji można utożsamić z jego realizacją przez jednostkę wykonawczą. ↩
-
Jeśli procesor zmienia częstotliwość pracy w trakcie swojego działania, wtedy iloraz wartości IPS do IPC może nie być równy częstotliwości taktowania (patrz "dynamiczna zmiana częstotliwości" w CPU > taktowanie oraz taktowanie a instrukcje wektorowe). ↩
-
materiał pochodzi z kursu SCIENTIFIC COMPUTING & VISUALIZATION, prowadzonego przez Aiichiro Nakano z USC (University of Southern California) ↩
-
materiał pochodzi z kursu Numerical Linear Algebra, prowadzonego przez Marka Arnolda z University of Arkansas ↩