OpenACC
![]()
Wprowadzenie¶
OpenACC to podobny do OpenMP, standard do zrównoleglania obliczeń na platformach akcelerowanych. Został zaprojektowany do ułatwienia prowadzenia obliczeń przede wszystkim na GPU. Może wspierać również inne typy akceleratorów. Wprowadził koncepcję delegowania obliczeń (tzw. offloading), która później została zaadaptowana przez standard OpenMP. Niektóre kompilatory umożliwiają wykonanie zrównoleglonego kodu zarówno na GPU jak i na wielordzeniowym CPU.
W czasie powstawania OpenACC programowanie akceleratorów GPU możliwe było tylko poprzez takie modele jak CUDA (dla GPU NVIDIA) czy OpenCL (różne akceleratory). Głównym założeniem OpenACC jest wykorzystanie akceleratorów GPU w jak najbardziej przystępny sposób, bez większej znajomości bazowego modelu dla danego sprzętu. Obecnie podobne funkcjonalności (tzw. GPU offloading) oferuje także standard OpenMP. Jednakże w porównaniu do OpenACC, kładzie on większy nacisk na udostępnienie bardziej precyzyjnej kontroli nad etapami akceleracji, przez co jest nieco bardziej złożony.
Standard OpenACC przewidziany jest dla akceleratorów różnego typu i różnych producentów. Warto jednak wiedzieć, że od samego początku był on rozwijany m.in. przez firmę NVIDIA i praktyczne implementacje zapewniały przede wszystkim wsparcie dla sprzętu tego producenta. Tak jest do dziś, a OpenACC jest promowany przez NVIDIA jako jeden z podstawowych modeli programowania swoich GPU.
Dostępność¶
Może być używany z językami programowania C, C++ oraz Fortran. Wymaga posiadania kompilatora, który udostępnia wsparcie dla OpenACC. Najbardziej dojrzałe są kompilatory firmy NVIDIA (nvc++, nvfortran). Wsparcie dostępne jest również w kompilatorach GNU (gcc, gfortran). Szczegóły w sekcji kompilatory.
Szczegóły¶
OpenACC bazuje na, podobnym do stosowanego w OpenMP, systemie dyrektyw umieszczanych w kodzie źródłowym. Ich rolą jest przekazanie dodatkowych informacji do kompilatora. W najprostszym przypadku dyrektywy wskazują bloki kodu przeznaczone do akceleracji (zrównoleglenia). Mogą one także zawierać bardziej szczegółowe instrukcje dotyczące zrównoleglenia obliczeń oraz transferów pamięci.
Dyrektywy¶
Dyrektywy OpenACC mają postać #pragma acc <nazwa_dyrektywy> <parametry_dyrektywy> (w przypadku C/C++)
lub !?acc … (Fortran). Należy umieszczać je w kodzie bezpośrednio przed blokiem kodu, którego mają dotyczyć. Dodatkowe
parametry dyrektywy są nazywane klauzulami (clauses).
Można wyszczególnić dwie najważniejsze kategorie dyrektyw oraz klauzul:
- zrównoleglanie obliczeń ─ dyrektywy wskazujące fragmenty kodu do zrównoleglenia (przede wszystkim pętle) oraz
opisujące szczegóły sposobu zrównoleglenia obliczeń; są to m.in. takie dyrektywy jak
kernels,parallel,loop; - zarządzanie pamięcią ─ dyrektywy zarządzające miejscem umieszczenia danych oraz transferami między pamięcią hosta,
a pamięcią akceleratora (dyrektywy
declare,data) oraz zasadami dostępu do danych (np. klauzulaprivate).
Dyrektywy mogą być łączone ze sobą, oraz mogą posiadać wiele klauzul zawierających dodatkowe parametry określające
zachowanie dyrektywy. Przykładowo #pragma acc parallel loop to połączenie dyrektyw parallel oraz loop,
natomiast #pragma acc data copy(...) to dyrektywa data posiadająca klauzulę copy.

schemat kodu z wykorzystaniem dyrektyw [źródło]
Zrównoleglanie obliczeń¶
W OpenACC podstawową jednostką kodu podlegającą zrównolegleniu jest pętla. Należy ją odpowiednio oznakować (
dyrektywa loop) oraz musi ona znajdować się w bloku równoległego kodu (dyrektywa parallel). Kod w
bloku parallel wykonuje się równolegle przez tzw. gangi. W momencie dotarcia do pętli oznakowanej jako loop,
iteracje pętli zostaną rozdzielone do wykonania między aktywne gangi. Istnieje również dyrektywa kernels, która
przerzuca odpowiedzialność za zrównoleglenie wskazanego bloku kodu na kompilator. W takiej sytuacji identyfikacja pętli
podlegających zrównolegleniu odbywa się automatycznie.

poziomy zrównoleglenia obliczeń w OpenACC [źródło]
OpenACC pozwala na określanie kilku poziomów równoległości: gangi, workery, wektory. Gang posiada wiele workerów, z
kolei worker jest reprezentowany przez wektor o zadanej długości. Podstawowe zrównoleglenie odpowiada uruchomieniu wielu
gangów (każdy reprezentujący pojedynczą jednostkę wykonania, tj. aktywny jest tylko jeden worker, o wektorze długości
jeden). Aby uruchomić dalszy podział obliczeń (aktywować wiele workerów wewnątrz gangu) należy podać odpowiednią
klauzulę. Do aktywacji oraz konfiguracji poszczególnych poziomów zrównoleglenia służą
klauzule gang, worker, vector.
Przykład wykorzystania klauzul gang oraz vector
#pragma acc kernels loop gang(32), vector(16)
for(auto i = 1; i < n - 1; ++i) {
B[i] = 0.25f * (A[i + 1] + A[i - 1]);
}
Pojęcia stosowane w OpenACC do opisu zrównoleglenia można odnieść do innych koncepcji znanych z klasycznych modeli programowania akceleratorów. Pojedynczą zrównolegloną pętlę można interpretować jako kernel (tj. funkcję wykonywaną na akceleratorze). Workery są odpowiednikami wątków (threads) z CUDA / HIP (patrz CUDA > hierarchia wątków) lub elementów roboczych (work-items) z SYCL (patrz SYCL > hierarchia obliczeń), a gangi – bloków lub grup roboczych. Z kolei wykorzystanie wektorów można utożsamić ze zrównolegleniem opartym o dwuwymiarowe bloki / grupy robocze.
Zarządzanie danymi¶
OpenACC zapewnia automatyczne zarządzanie transferami pomiędzy pamięciami hosta, a akceleratora. Domyślnie, dane są kopiowane do i z pamięci akceleratora dopiero wtedy, kiedy są wymagane do wykonania danego fragmentu kodu (w momencie pierwszego dostępu do nich). Jest to mechanizm analogiczny do tzw. unified (shared) memory znanego z innych modeli programowania akceleratorów.
Oprócz tego możliwe jest także ręczne przeprowadzanie transferów pamięci, które w wielu przypadkach może być
bardziej efektywne niż to generowane przez kompilator. Służy do tego dyrektywa data. Występująca samodzielnie
powoduje, że wszystkie wymagane transfery pamięci wykonywane są tylko na początku i na końcu bloku kodu, który obejmuje.
Może być rozwinięta o klauzule, z których najważniejsze to:
copyin─ wskazane rejony pamięci zostaną skopiowane z hosta do akceleratora na początku bloku objętego dyrektywą,copyout─ wskazane rejony pamięci zostaną skopiowane z akceleratora do hosta na końcu bloku objętego dyrektywą,copy─ łączy działanie powyższych (na początku dane zostaną skopiowane na akcelerator, a po wykonaniu obliczeń zostaną skopiowane z powrotem do pamięci hosta).
Klauzule dotyczące transferu danych mogą być także dodawane do dyrektyw kernels i parallel.
Przykładowo #pragma acc parallel copy(...) zachowa się jak blok kodu oznaczony jednocześnie dyrektywami parallel
oraz data.
Informacje o standardzie¶
OpenACC powstał w 2011 roku m.in. z inicjatywy firm NVIDIA, Cray oraz PGI (który później stał się częścią NVIDIA). Podstawowym celem było dostarczenie wysokopoziomowego standardu programistycznego bazującego na dyrektywach i przeznaczonego do użycia z akceleratorami takimi jak karty GPU. Zbliżony koncepcyjne standard OpenMP w tamtym czasie wspierał zrównoleglenie obliczeń tylko na CPU.
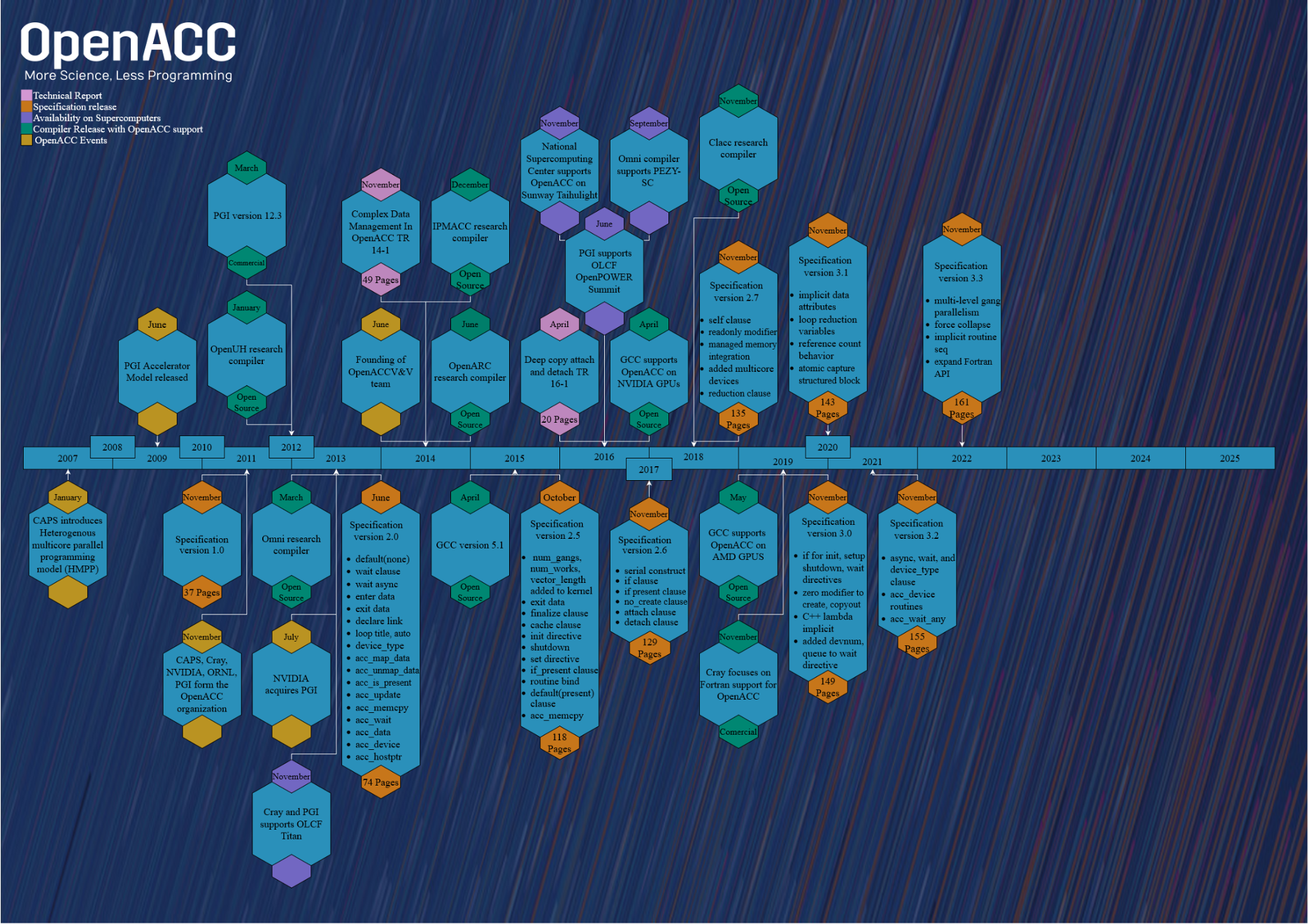
Obecnie standard jest systematycznie rozwijany przez OpenACC Organization. Organizacja ta skupia wiele firm oraz środowisk akademickich, a jej głównymi członkami są AMD, HPE, NVIDIA oraz ORNL. Aktualna wersja standardu OpenACC to 3.3, opublikowana w listopadzie 2022. Standard nie jest zbyt szybko wdrażany – wiodące kompilatory wspierają wersje 2.6 oraz częściowo 2.7 (wydane odpowiednio w 2017 oraz 2018 roku).

historia rozwoju OpenACC [źródło]
{kind=link}
Kompilatory¶
Do korzystania z OpenACC wymagane jest wsparcie ze strony kompilatora. Dostępny jest wykaz kompilatorów dla OpenACC. Spośród popularnych, najbardziej dojrzałe rozwiązanie dostarczają kompilatory NVIDIA oraz GNU. Należy mieć na uwadze, że zakres wspieranych akceleratorów (CPU, GPU AMD, GPU NVIDIA) zależy od kompilatora.
nvc++/nvfortran¶
Kompilatory firmy NVIDIA, dawniej rozwijane pod szyldem PGI. Wchodzą w skład NVIDIA HPC SDK. Umożliwiają kompilację kodu z dyrektywami OpenACC zarówno na platformy GPU NVIDIA, jak i pod kątem wielordzeniowych procesorów CPU. Implementują calość specyfikacji OpenACC 2.6 oraz większość elementów wersji 2.7.
Więcej informacji¶
gcc/gfortran¶
Powszechnie znane, otwartoźródłowe kompilatory z inicjatywy GCC (GNU Compiler Collection). Najnowsza wersja gcc 13.2
implementuje OpenACC 2.6. Wspiera offloading zarówno na GPU NVIDIA jak i GPU AMD. Wsparcie OpenACC w GCC jest
jednak zdecydowanie mniej dojrzałe niż w kompilatorach NVIDIA. Jednym z ograniczeń jest brak możliwości zrównoleglania
obliczeń na CPU (możliwe jest jedynie uruchamianie jednowątkowe). Kod OpenACC skompilowany przy użyciu gcc może być
mniej wydajny w porównaniu z kompilacją nvc++.
Więcej informacji¶
pozostałe¶
Istnieją także inne kompilatory OpenACC, zazwyczaj przeznaczone dla konkretnych platform sprzętowych lub rozwijane jako projekty badawcze. Spośród nich warty wspomnienia jest kompilator Sourcery CodeBench przewidziany do kompilacji OpenACC pod kątem GPU AMD (posiada wsparcie dla najnowszych GPU firmy AMD, np. MI200). Bazuje on na wersjach rozwojowych gcc i uwzględnia dodatkowe optymalizacje dla platform AMD.
Linki¶
- strona OpenACC
- dokumentacja
- specyfikacja (obecne i poprzednie wersje)
- przewodnik dla programisty
- materiały