MPI
![]()
Wprowadzenie¶
MPI (Message Passing Interface) to powszechnie używany standard do zrównoleglania obliczeń w architekturze rozproszonej, tj. między wieloma komputerami połączonymi w sieć. Oparty o procesy z oddzielną pamięcią, może zostać wykorzystany również w obrębie jednego komputera. Bardzo często jest łączony z innymi technologiami odpowiedzialnymi za dalsze zrównoleglenie obliczeń na wiele wątków lub akceleratory (np. OpenMP, CUDA lub HIP).
Dostępność¶
Standard MPI określa interfejs programistyczny (API) dla języków C/C++ oraz Fortran. Jest on realizowany w formie zewnętrznej biblioteki. Istnieje jego wiele implementacji. Można również znaleźć rozwiązania dla innych języków programowania, np. mpi4py dla języka Python.
Programy korzystające z MPI kompiluje się standardowymi kompilatorami (np. gcc, icx, nvc++) za pośrednictwem wrapperów np. mpicc lub mpifort. Wrappery wywołują bazowy kompilator, ustawiając ścieżkę dostępu do danej biblioteki MPI oraz inne potrzebne flagi kompilatora.
Inne technologie¶
MPI może być łączony z innymi technologiami, odpowiedzialnymi za zrównoleglenie obliczeń w obrębie jednej maszyny (wielowątkowość, akceleratory) np. takimi jak OpenMP czy CUDA lub HIP. Takie połączenie jest nazywane kodem hybrydowym (tzw. MPI+X). Popularnymi rozwiązaniami są kody MPI+OpenMP lub MPI+CUDA.
W przypadku akceleratorów GPU, implementacje MPI wspierają techniki DMA (direct memory access) oraz RDMA (remote direct memory access) czyli bezpośrednie przesyłanie danych z/do pamięci GPU. Dotyczy to zarówno komunikacji w obrębie jednego komputera (DMA) jak i przez sieć (RDMA). Dla oznaczenia tego wsparcia używa się określenia CUDA-aware MPI (wsparcie dla modelu NVIDIA CUDA) bądź GPU-Enabled MPI (wsparcie dla GPU AMD, bardziej szczegółowo określane jako ROCm-aware MPI).
Szczegóły¶
Zrównoleglanie w MPI odbywa się poprzez uruchomienie wielu procesów. Każdy z nich posiada swoją pamięć i każdy może wykonywać zupełnie inny kod (tzw. model MIMD lub MPMD – Multiple Instruction/Program Multiple Data). Najczęściej jednak uruchamia się wiele instancji tego samego programu (tzw. model SPMD – Single Program Multiple Data), a zróżnicowanie zachowania procesów odbywa się na poziomie kodu źródłowego.
Procesy MPI mogą wykonywać się w obrębie tego samego komputera lub na różnych komputerach połączonych w sieć. Ponieważ każdy program wykonuje się w sposób niezależny i potencjalnie na innej maszynie, taki sposób zrównoleglenia określa się jako rozpraszanie obliczeń. Szczegóły startowania programu MPI są opisane w sekcji uruchamianie programu.

model programu MPI, wiele procesów komunikujących się ze sobą przez sieć [źródło]
Podstawą komunikacji w MPI jest przesyłanie wiadomości (stąd nazwa message passing) – każdy proces może wysłać dane do innego procesu lub grupy procesów. Komunikacja odbywa się poprzez komunikator, w ramach którego każdy proces otrzymuje swój unikatowy identyfikator (rank). Pozwala to na adresację wiadomości bezpośrednio do konkretnego procesu, jak i na wspomniane zróżnicowanie zachowania procesów w ramach jednego kodu źródłowego.

komunikacja między dwoma procesami [źródło]
Przesyłanie danych polega na wskazaniu bufora (tablicy) w pamięci programu, typu danych oraz ich ilości. Dane z procesu nadawcy zostaną skopiowane do bufora w pamięci procesu odbiorcy. Funkcje i typy danych z MPI można łatwo zidentyfikować w kodzie źródłowym. Ich nazwy zaczynają się od przedrostka MPI_. Oprócz przesyłania danych możliwe jest również synchronizowanie procesów poprzez wywołanie tzw. bariery (funkcja MPI_Barrier).
Programy korzystające z MPI muszą dokonać inicjalizacji biblioteki (każdy proces z osobna) poprzez wywołanie funkcji MPI_Init. Po zakończeniu obliczeń każdy proces powinien zakończyć korzystanie z MPI poprzez MPI_Finalize.
Sesje MPI
Konieczność inicjalizowania środowiska MPI mogła prowadzić do problemów w przypadku złożonych aplikacji odwołujących się do bibliotek korzystających z MPI. Aby rozwiązać ten problem standard MPI-4.0 wprowadził sesje – dodatkowy mechanizm pozwalający na izolację wykorzystania biblioteki MPI.
Dzięki niemu każdy komponent aplikacji może w sposób niezależny dokonać inicjalizacji biblioteki MPI poprzez zainicjowanie swojej sesji. Komunikacja w obrębie jednej sesji nie wpływa na inne sesje, a więc każdy komponent może korzystać z MPI, bez obawy o zakłócenie komunikacji prowadzonej przez inny komponent tej samej aplikacji.
Przykładowy program¶

przykładowy program MPI w języku C [źródło]
Po zainicjowaniu środowiska MPI proces pobiera informację o ilości procesów w domyślnym komunikatorze (MPI_COMM_WORLD) oraz o swoim identyfikatorze (rank). Proces o identyfikatorze 0 wysyła wiadomości kolejno do wszystkich pozostałych procesów. Więcej szczegółów oraz wersja Fortran powyższego przykładu znajdują się w omówieniu przykładowego programu.
Kompilacja programu MPI
Do kompilacji używa się najczęściej wrapperów mpicc, mpicxx lub mpifort. Nie są to osobne kompilatory, ich jedynym zadaniem jest ułatwienie linkowania z biblioteką MPI. Wywołują one standardowy kompilator z odpowiednimi flagami wskazującymi lokalizację danej biblioteki MPI. Polecenie mpicc -show wypisze właściwa komendę dla docelowego kompilatora.
Uruchamianie programu¶
Program MPI uruchamia się korzystając z tzw. launchera – programu którego zadaniem jest uruchomienie procesów na dostępnych maszynach i zasobach, według zadanej konfiguracji. Takim launcherem jest komenda mpiexec (lub mpirun która zazwyczaj jest aliasem).
Składnia polecenia mpiexec
mpiexec [argumenty_launchera] program [argumenty_programu]
Podstawowa opcja -n pozwala na określenie ile procesów ma zostać uruchomionych.
Przykład uruchomienia
Poniższa komenda uruchomi cztery instancje (procesy) programu ./test z argumentami arg1 arg2 …:
mpiexec -n 4 ./test arg1 arg2 …
Dodatkowe opcje pozwalają:
- określić mapowanie procesów (process mapping), czyli w jaki sposób procesy mają zostać rozmieszczone pomiędzy maszyny i dostępne zasoby CPU,
- zdefiniować przypinanie procesów (process pinning lub process binding), czyli w jaki sposób fizyczne rdzenie mają zostać przydzielone do procesów,
- podać inne szczegółowe argumenty specyficzne dla danej implementacji MPI.
Bardzo użyteczną funkcjonalnością jest rozróżnianie standardowego wyjścia (outputu) dla różnych procesów. W tym zakresie możliwe jest:
- ustawienia zapisu outputu do osobnych plików dla każdego procesu,
- włączenie znakowania, który proces wypisał którą linijkę.
Argumenty launchera
Opcje uruchomienia i dodatkowe funkcjonalności zależą od poszczególnych implementacji.
Warto wiedzieć, że w przypadku klastrów obliczeniowych opartych o system kolejkowy SLURM, zazwyczaj komenda srun może również być stosowana do uruchamiania programów MPI. W takiej sytuacji wywołanie srun przekłada się na zrównoleglenie tożsame z wywołaniem mpiexec.
Warianty komunikacji¶
W standardzie MPI dostępne są różne formy komunikacji. Każda z nich stwarza inne możliwości wymiany danych między procesami. Czasami tę samą funkcjonalność da się zrealizować na kilka różnych sposobów i każdy z nich może oferować inną wydajność. Zasadniczo można wyróżnić komunikację bezpośrednią (dot. pary procesów) oraz grupową (dot. wielu procesów).
Komunikacja bezpośrednia (point-to-point) zachodzi między parą procesów. Dane między procesami można wymieniać dwoma technikami.
- komunikacja dwustronna ─ Oparta o model send-receive w którym nadawca wysyła dane, a odbiorca przyjmuje je. Aby doszło do wymiany danych konieczne jest wywołanie odpowiednich funkcji przez obydwa procesy (
MPI_Sendpo stronie nadawcy, orazMPI_Recvpo stronie odbiorcy). Na wiadomość składają się dane oraz informacje adresowe (tzw. envelope). Poniżej opisane są tryby wysyłania wiadomości.

schemat komunikacji dwustronnej [źródło]

składnia funkcji – część dot. danych [źródło]

składnia funkcji – adresacja wiadomości [źródło]
- komunikacja jednostronna (one-sided) ─ Oparta o mechanizm RMA (Remote Memory Access) w którym jeden proces może pobrać (
MPI_Get) lub umieścić (MPI_Put) dane bezpośrednio w pamięci innego procesu. Ta forma komunikacji wymaga najpierw zdefiniowania przez każdy proces fragmentu swojej pamięci – tzw. okienka (window) – który będzie dostępny dla innych procesów w komunikatorze. Następnie pojedynczy proces może samodzielnie pobrać dane z pamięci innego procesu (bez konieczności wywoływania funkcji przez ten drugi proces).

schemat komunikacji jednostronnej [źródło]
Komunikacja grupowa (collective) pozwala na kilka schematów współpracy i wymiany danych w ramach grupy procesów:
- replikacja danych z jednego procesu do grupy procesów (broadcast),
- podział danych między grupę procesów (scatter),
- zgromadzenie danych z grupy procesów (gather),
- obliczanie wyrażeń na danych z grupy procesów (reduce, scan),
- synchronizacja procesów (barrier).
Operacje dotyczące grupy procesów określa się jako operacje kolektywne. Aby taka funkcja została wykonana musi ona zostać wywołana przez wszystkie procesy z danego komunikatora.

komunikacja grupowa, przykłady funkcji kolektywnych [źródło]
Oprócz powyższych operacji w modelu proces – grupa procesów, są również warianty gdzie wszystkie procesy wysyłają i odbierają dane (all-to-all, all-gather, all-reduce).

funkcje kolektywne typu all-to-all [źródło]
Tryby wysyłania wiadomości¶
Oprócz różnych schematów komunikacji, MPI dostarcza kilka trybów przesyłania wiadomości. W rezultacie ta sama operacja może zostać zrealizowana na kilka sposobów: w trybie synchronicznym lub buforowanym oraz blokującym lub nieblokującym.
Zagadnienie to dotyczy głównie klasycznego schematu przesłania wiadomości w komunikacji dwustronnej:
- nadawca woła
send(i zawiesza swoje działanie) - odbiorca woła
recv(i zawiesza swoje działanie) - następuje przesłanie wiadomości, po czym obydwa procesy mogą kontynuować swoje działanie.
Powyższy schemat komunikacji synchronicznej, w której jeden proces blokuje swoje działanie, do czasu wywołania odpowiedniej funkcji przez drugi proces, jest pewnym uproszczeniem. Otóż standard MPI pozwala na dużo więcej niż tylko komunikacja synchroniczna.

model komunikacji synchronicznej [źródło]
Podstawowy mechanizm w MPI zakłada buforowanie wiadomości. W związku z tym, w momencie gdy wiadomość zostaje nadana (MPI_Send), dane do wysłania mogą zostać skopiowane do wewnętrznego bufora biblioteki i tam czekać na wysłanie. Dzięki temu operacja wysyłania danych z perspektywy nadawcy może zostać ukończona zanim odbiorca zgłosi się po odbiór wiadomości (tj. zanim wywoła MPI_Recv). Trzeba jednak mieć na uwadze, że w momencie gdy zbyt dużo wiadomości jest zbuforowanych, MPI_Send może wstrzymać dalsze wykonanie procesu nadawcy. Również samo kopiowanie wiadomości do wewnętrznego bufora może wymagać czasu, dlatego podstawowe funkcje określa się jako funkcje blokujące.

model komunikacji buforowanej [źródło]
Dla uniknięcie sytuacji zablokowania procesu na faktycznym wysyłaniu/odbieraniu wiadomości lub na buforowaniu, MPI dostarcza funkcje nieblokujące (non-blocking). Można je rozpoznać po literze I w nazwie funkcji (od immediate), np. MPI_Isend lub MPI_Irecv. Idea tych operacji jest taka, że nadawca/odbiorca niejako zleca bibliotece MPI wykonanie odpowiednio wysłania/odebrania danych. Funkcje te od razu zwracają sterowanie do programu, nie czekając na zrealizowanie operacji przesyłania danych (które tak jakby wykonuje się w tle). Następnie nadawca/odbiorca może sprawdzić status wykonania operacji (MPI_Test). Mogą również zażądać ukończenia operacji (MPI_Wait) co wprowadza ich w stan blokujący.
Zasadniczym celem funkcji nieblokujących jest możliwość jednoczesnego komunikowania się przez jeden proces z wieloma innymi procesami. Pozwala to również na nałożenie na siebie fizycznej komunikacji oraz obliczeń.
Operacje nieblokujące a asynchroniczność
Można ulec wrażeniu, że operacje nieblokujące wykonują się w sposób asynchroniczny, równolegle do działania programu użytkownika. To czy tak jest zależy od implementacji biblioteki MPI lub jej ustawień. Standard MPI pozwala na zachowanie w którym cała operacja wykona się w trakcie któregoś odwołania do biblioteki, np. dopiero w momencie wywołania końcowego MPI_Wait.
Co ciekawe, standard MPI pozwala na dokładne określenie przez programistę jakie zachowanie ma być zrealizowane przez bibliotekę. W efekcie dostępnych jest wiele funkcji do wysłania pojedynczej wiadomości, co może wzbudzić pewne zmieszanie u początkującego użytkownika.
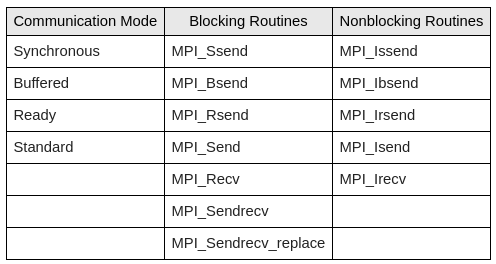
zestawienie różnych funkcji do komunikacji dwustronnej [źródło]
MPI_Ssend, wysłanie synchroniczne ─ sterowanie zostanie zwrócone gdy odbiorca faktycznie odbierze wiadomość;MPI_Bsend, wysłanie buforowane ─ sterowanie zostanie zwrócone gdy dane z pamięci programu zostaną skopiowane do bufora (zdefiniowanego przez użytkownika); po wykonaniu tej funkcji nadawca może bezpiecznie modyfikować dane w swojej pamięci i nie wpłynie to na zbuforowane dane oczekujące na wysłanie;MPI_Rsend, to tzw. "ready-send" ─ dodatkowa funkcja możliwa do użycia tylko w sytuacji gdy nadawca ma gwarancję, że odbiorca wywołał już po swojej stronie funkcjęMPI_Recv(jeśli tak nie jest, wywołanie może spowodować błąd programu);MPI_Send, wysłanie standardowe ─ może się okazać synchronicznym lub buforowanym (przy czym do buforowania jest wykorzystywany wewnętrzny bufor biblioteki); zachowanie zależy od implementacji.
Nieblokujące odpowiedniki powyższych to MPI_Issend, MPI_Ibsend, MPI_Isend. Wszystkie tryby nadawania wiadomości odbiera się poprzez blokujące wywołanie MPI_Recv lub nieblokujące MPI_Irecv.
Komunikacja grupowa również posiada nieblokujące odpowiedniki swoich wywołań.
Komunikator¶
Podstawowym mechanizmem o który oparte jest przesyłanie wiadomości jest komunikator. Po starcie programu wszystkie procesy należą do jednego komunikatora o nazwie MPI_COMM_WORLD. W trakcie dalszej pracy programu możliwe jest:
- utworzenie kopii komunikatora,
- podział komunikatora na mniejsze komunikatory.
Kopia komunikatora pozwala na izolowanie od siebie różnych wiadomości (patrz parowanie wywołań), czyli tak jakby dodanie równoległej warstwy do komunikacji między tą samą grupą procesów. Podział komunikatora pozwala natomiast na podzielenie wszystkich procesów na mniejsze podgrupy. Dzięki temu możliwe staje się prowadzenie operacji kolektywnych tylko na wybranej grupie.

przykład podziału procesów na dwa dodatkowe komunikatory [źródło]

przykład nakładania się kilku komunikatorów [źródło]
Podsumowując, komunikator można utożsamiać z grupą procesów, które są w stanie wymieniać między sobą wiadomości, a każdy proces może należeć do kilku komunikatorów. W interfejsie MPI odzwierciedla się to poprzez podawanie do większości funkcji zmiennej typu MPI_Comm identyfikującej komunikator.
Dodatkowa możliwość oferowana przez MPI to wirtualna topologia, którą można nadać tworząc w specjalny sposób nowy komunikator. Pozwala ona na zorganizowanie procesów na dwa sposoby:
- wielowymiarowa siatka (cartesian topology), w której pomocnicze funkcje pozwalają określić, kto jest sąsiadem w danym wierszu/kolumnie,
- forma grafu, w której dla każdego procesu jest jawnie określone, kto jest jego sąsiadem.

wirtualne topologie grupy procesów w formie siatki 2D oraz grafu [źródło]
Wprowadzenie topologii pozwala na bardziej naturalne wyrażenie schematu komunikacji i wykonywanie operacji dotyczących tylko sąsiadów danego procesu.
Parowanie wywołań¶
Podstawowym zagadnieniem związanym z przesyłaniem wiadomości jest kwestia odpowiedniego parowania ze sobą operacji send i recv wywołanych przez różne procesy. Warto zdać sobie sprawę, że w danym momencie możliwe jest, że do tego samego procesu zostały wysłane wiadomości od wielu różnych procesów. Pokrewnym zagadnieniem jest możliwość izolowania od siebie wiadomości, a więc zagwarantowanie przez programistę, że pewne wywołania funkcji MPI nie zostaną omyłkowo sparowane ze sobą.
Wszystkie wiadomości są wysyłane i odbierane w ramach komunikatora. Oznacza to, że operacje dot. różnych komunikatorów nie mogą zostać ze sobą sparowane. W przypadku komunikacji dwustronnej, poza określeniem jakie dane są wysyłane, każda wiadomość zostaje zaadresowana poprzez:
- identyfikator nadawcy,
- identyfikator odbiorcy,
- dodatkowy tag, czyli identyfikator danej wiadomości.

przykład oczekiwanego sparowania [źródło]

błędne sparowanie (zawieszenie programu) [źródło]
Nadawca nadając wiadomość, podaje do kogo ją wysyła. Z kolei odbiorca podaje, od którego procesu spodziewa się wiadomości (możliwe jest również zadeklarowanie, że chce się otrzymać wiadomość od dowolnego nadawcy). Taka adresacja już pozwala na rozróżnienie między sobą wiadomości pochodzących od różnych procesów. Dodatkowy tag pozwala na jeszcze większe rozróżnienie między sobą przesyłanych wiadomości. Może to pozwolić np. na jednoczesne przesyłanie kilku wiadomości między tą samą parą procesów, bez obawy o błędne sparowanie wywołań. Innym zastosowaniem może być czekanie przez odbiorcę na wiadomość o dowolnym tagu i różnicowanie swojego zachowania w zależności od identyfikatora jaki posiada odebrana wiadomość.
Typy danych¶
Wysyłając dane, określa się liczbę przesyłanych elementów oraz typ danych pojedynczego elementu. Standard MPI definiuje podstawowe typy danych (basic datatypes), które mniej więcej odpowiadają podstawowym typom z języka C oraz Fortran. Przykładowo MPI_INT to odpowiednik int w C, natomiast MPI_INTEGER to odpowiednik integer w Fortran. Szczegółowy wykaz – patrz tabela podstawowych typów.
Możliwe jest również tworzenie swoich własnych typów, określanych jako złożone typy danych (derived datatypes). Pozwalają one na zgrupowanie ze sobą w pojedynczym elemencie wielu elementów o różnych podstawowych typów. Co więcej, bazowe elementy nie muszą znajdować się w spójnym bloku pamięci. Dzięki temu możliwe jest stworzenie typu danych odpowiadającego własnej strukturze danych (struct w C) albo typu grupującego elementy wiersza bądź kolumny z dwuwymiarowej tablicy.

przykład typu który odpowiada wielu elementom innego typu [źródło]

przykład typu dla struktury przechowującej 3 wartości int oraz 5 wartości double [źródło]
Podsumowując, złożone typy pozwalają na wyrażanie dowolnych wzorców ułożenia danych w pamięci programu. Ich stosowanie pozwala na zwiększenie wydajności komunikacji – programista nie musi ręcznie kopiować danych do osobnych tablic, a biblioteka MPI może optymalizować sposób wysyłania dla poszczególnych wzorców.
Więcej informacji:
Optymalizacje dla shared-memory¶
Uruchamiając program MPI specyfikuje się ile procesów ma zostać wykonanych na której maszynie. Przykładowo uruchamiamy 8 instancji danego programu na dwóch maszynach – po 4 procesy na każdym komputerze. Tymczasem z perspektywy logicznej, program MPI nie rozróżnia, które procesy znajdują się na tej samej maszynie, a które nie (adresacja wiadomości jest tylko po identyfikatorze procesu w danym komunikatorze). Warto jednak wiedzieć, że standard MPI i jego implementacje udostępniają kilka udogodnień, które wspierają prowadzenie wydajnych obliczeń w obrębie tej samej maszyny. Optymalizacje te umożliwiają skorzystanie z tego, że procesy w obrębie tej samej maszyny mogą korzystać ze wspólnej pamięci RAM.
- Kiedy wiadomość jest przesyłana między dwoma procesami znajdującymi się na tej samej maszynie, dane są kopiowane między tymi procesami, bez interakcji z warstwą sieciową.
- Uruchamiając program, można określić sposób rozdzielania kolejnych procesów (tj. nadawania im identyfikatorów) między maszyny. Mając to na uwadze, programista może napisać kod, który będzie działał wydajniej dla konkretnej strategii przypisania procesów do maszyn.
- Standard MPI pozwala na zgrupowanie ze sobą procesów, które znajdują się na tej samej maszynie (patrz funkcja
MPI_Comm_split_typeoraz parametrMPI_COMM_TYPE_SHARED). Możliwy jest również dalszy podział na podgrupy w oparciu o szczegóły dotyczące sprzętu – np. zgrupowanie ze sobą procesów przypiętych do tego samego węzła NUMA w procesorze CPU (patrz parametrMPI_COMM_TYPE_HW_GUIDED). Poszczególne implementacje dostarczają również swoje własne, niestandardowe sposoby podziału komunikatora. - Standard MPI został wyposażony we wsparcie dla modelu pamięci współdzielonej. Służy do tego tworzenie "wspólnego okienka" poprzez procesy z tej samej maszyny (
MPI_Win_allocate_shared). Mechanizm przypomina komunikację jednostronną, z tym że po utworzeniu okienka dane można umieszczać tam bezpośrednio (bez wołaniaMPI_Put/Get.
Wielowątkowość¶
Standard MPI powstał w czasach, gdy pojedynczy komputer posiadał tylko jeden procesor (z jednym rdzeniem obliczeniowym), a aplikacje były jednowątkowe. Wraz z upływem czasu i popularyzacją maszyn wielordzeniowych, dodane zostało wsparcie dla programów, które wykorzystują wiele wątków. Aby z niego skorzystać trzeba zainicjować bibliotekę poprzez wywołanie MPI_Init_thread (zamiast MPI_Init) i określić w jakim trybie wsparcia dla wielowątkowości biblioteka MPI będzie wykorzystywana.
Tryb pracy wielowątkowej z MPI
MPI_THREAD_SINGLE– klasyczna jednowątkowa aplikacja,MPI_THREAD_FUNNELED– proces może mieć wiele wątków, ale tylko główny wątek będzie korzystał z MPI,MPI_THREAD_SERIALIZED– wszystkie wątki mogą korzystać z MPI, ale tylko jeden w danym momencie,MPI_THREAD_MULTIPLE– pełne wsparcie, wszystkie wątki mogą korzystać z MPI równolegle do siebie.
Przestrzeganie danego trybu pracy z biblioteką MPI leży w gestii programisty. Według standardu to czy dany poziom wsparcia jest obsługiwany jest zależne od implementacji. Jednak obecnie wszystkie główne implementacje udostępniają pełne wsparcie dla pracy wielowątkowej.
Należy mieć na uwadze, że włączenie wsparcia dla pracy wielowątkowej może oznaczać pewien narzut (głównie pamięciowy) w pracy z MPI.
Identyfikator procesu a wielowątkowość
Adresacja w MPI uwzględnia tylko identyfikator procesu w ramach danego komunikatora. Programując wiele wątków wysyłających i odbierających wiadomości w ramach tego samego procesu, trzeba być bardzo ostrożnym – bardzo łatwo o pomyłkę i odebranie przez dany wątek nie tej wiadomości, na którą czekamy. Rozwiązaniem może być odpowiednie zastosowanie tagów wiadomości.
Nowym wyjściem naprzeciw programom wielowątkowym (np. MPI+OpenMP) jest koncepcja komunikacji podzielonej na części (partitioned communication), która została wprowadzona w standardzie 4.0. Pozwala ona na rozpoczęcie komunikacji (MPI_Psend_init) i przygotowanie osobno każdej porcji danej wiadomości (MPI_Pready). Dzięki takiemu podejściu, każdy fragment wiadomości może zostać obsłużony przez inny wątek. Należy mieć na uwadze, że to rozwiązanie jest dopiero wdrażane do najnowszych implementacji standardu MPI.
Warstwa sieciowa (interconnect)¶
Warto zdać sobie sprawę, że jeśli chodzi fizyczną komunikację sieciową, zarówno dawniej jak i obecnie, dostępnych jest wiele rozwiązań sprzętowych. Chodzi o takie komponenty jak karty sieciowe oraz przełączniki (tzw. switche), a także sposób ich połączenia. W kontekście klastrów obliczeniowych określa się je jako interconnect (czasem jako fabric). Jest to szybka sieć łącząca ze sobą wiele węzłów obliczeniowych. Popularne obecnie rozwiązania (i ich producenci) to m.in.
- Ethernet,
- InfiniBand (Nvidia, dawniej Mellanox),
- Omni-Path (Intel),
- Slingshot (HPE, dawniej Cray).
Każde z nich na poziomie sprzętowym zachowuje się inaczej – posiada swój niskopoziomowy protokół przesyłania danych i swoje specyficzne możliwości, w tym mechanizmy akceleracji sprzętowej operacji typowych dla MPI.
MPI powstał jako (stosunkowo) wysokopoziomowy standard, który ma gwarantować przenośność między różnymi architekturami – w tym, a może przede wszystkim, różnymi architekturami niskopoziomowej warstwy komunikacji sieciowej. Z perspektywy programisty to na jakim sprzęcie pod spodem wykonuje się przesyłanie wiadomości nie ma większego znaczenia. Jednakże podstawowe rozeznanie może być przydatne.
- Obsługa danego interconnectu jest zależna od implementacji MPI. Historycznie poszczególne implementacje były skupione na konkretnym rodzaju sprzętu. Obecnie główne implementacje obsługują większość popularnych rozwiązań, mogą jednak występować pewne ograniczenia.
- Niskopoziomowe (bliskie sprzętu) warstwy komunikacji są określane mianem transportów. Przykładowo, dla InfiniBand możemy mówić o ib verbs lub rdma, a w ich ramach o protokołach/transportach UD, UC, RC. Dla klasycznego Ethernetu mamy TCP. Dla Omni-Path jest to PSM2. Możemy również mówić o transportach dla GPU, które pozwalają na przesyłanie danych bezpośrednio do/z pamięci GPU – w tym kontekście będzie to CUDA (dla NVIDIA) oraz ROCm (dla AMD).
- Komunikacja wewnątrz węzła traktowana jest jako jeden z rodzajów transportów (shared-memory). Bardziej szczegółowo w jego ramach można wyróżnić kilka rozwiązań (np. SHM oraz mechanizmy CMA, KNEM, XPMEM unikające tzw. double-copy, czyli podwójnego kopiowania pamięci).
- Dla danej instalacji biblioteki MPI można mówić o tym jakie transporty obsługuje. Co więcej, niektóre implementacje dostarczają możliwość sterowania tym, które transporty mogą zostać użyte dla danego wykonania programu. Stwarza to możliwość poprawy wydajności, poprzez wybór odpowiedniego transportu. W większości przypadków współczesne biblioteki posiadają mechanizmy dobierające optymalne ustawienia za użytkownika.
-
Między wysokopoziomową warstwą komunikacji jaką jest MPI a sprzętową realizacją przesyłu danych obecnie najczęściej stosuje się warstwę pośrednią, która unifikuje obsługę różnych rodzajów interconnect. Dodatkowo taka warstwa pośrednia pozwala na równoległe wykorzystanie kilku różnych transportów. Dwie najpopularniejsze biblioteki pośredniczące to:
- libfabric znana również jako OFI czyli Open Fabric Interfaces (repozytorium),
- UCX czyli Unified Communication X (repozytorium).
Współczesne implementacje MPI posiadają backendy komunikacyjne oparte o któreś z tych dwóch rozwiązań, co automatycznie umożliwia danej implementacji integrację z wieloma interconnectami.

OFI jako wspólny interfejs dla wielu transportów przewidzianych dla różnych rozwiązań sprzętowych [źródło]

obsługa różnych transportów na przykładzie UCX [źródło]
Hierarchiczność warstw komunikacji – od biblioteki MPI, przez warstwę pośrednią libfabric / UCX, do niskopoziomowego transportu – oznacza, że na każdym z tych poziomów można szukać okazji do optymalizacji wydajności. Poszczególne rozwiązania mogą udostępniać możliwość wpływu na ich zachowanie np. poprzez zmienne środowiskowe.
Informacje o standardzie¶
MPI to dojrzały i powszechny standard, który posiada długą historię (początki w 1994 roku). Za jego rozwój odpowiada MPI Forum – szerokie grono złożone z badaczy z wielu instytucji naukowych oraz firm produkujących sprzęt HPC. Po pewnym przestoju, od roku 2008 standard jest systematycznie rozwijany i dostosowywany do możliwości sprzętowych oraz aktualnych potrzeb wysoce skalowalnych obliczeń.
W roku 2021 został wydany standard MPI 4.0. Obecnie trwają prace nad wersjami 4.1 (drobne poprawki do aktualnego standardu) oraz 5.0 (nowe funkcjonalności). Jednym z omawianych kierunków rozwoju jest zwiększenie wsparcia dla modelu MPI+GPU. Należy mieć na uwadze, że poszczególni implementatorzy (dostawcy bibliotek MPI) stopniowo wdrażają najnowsze funkcjonalności (patrz status wdrożenia standardu).
Proces rozwoju standardu MPI
Rozwój standardu odbywa się w mocno jawny i demokratyczny sposób. Grupy robocze, rozważane zagadnienia oraz materiały pomocnicze, a także agenda spotkań, czy informacje o głosowaniach – to wszystko można znaleźć na podstronie dokumentującej prace nad kolejną wersją oraz na innych podstronach.
Standard MPI posiada przemyślane nazewnictwo oraz dobrze zdefiniowane pojęcia do opisu zachowania funkcji. Po zapoznaniu się z podstawami, warto pogłębić swoją wiedzę poprzez lekturę terminologii (rozdział "MPI Terms and Conventions" z oficjalnego standardu).
Ewolucja standardu
Informacje na temat ewolucji standardu można znaleźć w następujących miejscach:
- krótka historia MPI (do 2020 roku, brak aktualizacji dla MPI-4.0)
Bardziej szczegółowy opis dostępny jest na pierwszych stronach oficjalnego standardu.
Implementacje¶
Standard MPI posiada wiele implementacji. Można je podzielić na:
- publicznie dostępne, otwartoźródłowe implementacje (takie jak MPICH, Open MPI, czy MVAPICH), które przeważnie są rozwijane pod opieką środowiska naukowo-badawczego;
- komercyjne, rozwijane głównie przez producentów sprzętu lub dostawców oprogramowania (np. Intel MPI, HPE Cray MPI).
Historycznie mnogość implementacji wynikała z tego, że każda obsługiwała tylko sprzęt sieciowy danego producenta. Obecnie większość implementacji obsługuje wiele rodzajów interconnect (m.in. dzięki integracji z warstwą pośrednią libfabric/OFI bądź UCX). Rozwiązania producentów zwykle bazują na publicznie dostępnych implementacjach i optymalizują je pod kątem wykorzystanie danego sprzętu. Bardzo często dystrybucje MPI są elementem środowiska programistycznego dostarczanego przez danego producenta.
Funkcjonalność instalacji MPI
Należy mieć na uwadzę, że zakres wspieranych rozwiązań sprzętowych zależy od sposobu instalacji (kompilacji) danej biblioteki. Pracując z gotową instalacją na klastrze obliczeniowym, może się okazać że nie wspiera ona jakiegoś rozwiązania, pomimo tego że dana implementacja oferuje takowe wsparcie. Z tego też względu na klastrach obliczeniowych można czasem znaleźć kilka modułów dotyczących tej samej biblioteki MPI – każda skompilowana w inny sposób.
Różnice między implementacjami
Z perspektywy programistycznej, właściwie nie ma znaczenia która implementacja MPI jest wykorzystywana. Wszystkie zachowują się w sposób zgodny ze standardem MPI. Jedyne różnice mogą dotyczyć tego czy dana implementacja wspiera wszystkie funkcjonalności ze standardu. W przypadku najnowszych funkcjonalności ich użycie może zawęzić przenośność kodu tylko do tych implementacji które już wdrożyły daną funkcjonalność. Ewentualnie w programie można wykorzystać pewne rozszerzenia specyficzne dla danej implementacji (np. OMPI_COMM_TYPE_NUMA z Open MPI, albo MPIX_COMM_TYPE_NEIGHBORHOOD z MPICH dotyczące podziału komunikatora).
Przenośność kodu MPI a wydajność
Schematy komunikacji w MPI można realizować na kilka sposobów. Na pytanie, który z nich jest najwydajniejszy nie ma ogólnej odpowiedzi, gdyż wydajność programów MPI nie jest przenośna. Każda implementacja może osiągać najlepszą wydajność dla innego schematu komunikacji. Co więcej wydajność komunikacji dla danego schematu może być różna w zależności od wielkości przesyłanych wiadomości.
Największe różnice, poza zakresem wspieranych transportów i rozwiązań sprzętowych, dotyczą sposobów konfiguracji zachowania biblioteki MPI na etapie uruchomienia programu. Konfiguracja ta może odbywać się na dwa sposoby:
- poprzez argumenty komendy
mpiexecuruchamiającej program MPI, - poprzez zmienne środowiskowe.
Każda implementacja dostarcza swój zestaw argumentów i zmiennych środowiskowych. W tym miejscu przydaje się zrozumienie zależności między implementacjami – w momencie gdy jedna implementacja jest bazowana na innej, wtedy niektóre sposoby konfiguracji implementacji bazowej również mogą mieć wpływ na jej pochodną. Niektóre opcje konfiguracji mogą pochodzić od niższej warstwy tj. od OFI (libfabric) lub UCX.
MPICH¶
Jedna z pierwszych implementacji pierwszego standardu MPI. Częściowo traktowana jako implementacja referencyjna – jako jedna z pierwszych wdraża najnowsze funkcjonalności standardu MPI. Posiada niemal pełne wsparcie dla MPI-4.0. Implementacja MPICH stała się bazą dla wielu komercyjnych dystrybucji (np. dla Intel MPI, HPE Cray MPI, IBM MPI). Również MVAPICH wywodzi się z tej implementacji.
Mechanizm komunikacji w MPICH bazuje na tzw. urządzeniach (devices). Jest to pewna forma abstrakcji nad fizycznym sprzętem. Wspierane są dwa podstawowe urządzenia: ch4 (domyślne) oraz ch3, a także wiele innych, rozwijanych przez zewnętrznych dostawców.
- ch4 ─ nowsze rozwiązanie, bazuje na różnych modułach komunikacji sieciowej oraz pamięci współdzielonej, w szczególności posiada moduł ofi oraz ucx,
- ch3 ─ udostępnia do komunikacji tzw. kanały, obecnie wspierane są dwa: uniwersalny kanał nemesis (wsparcie dla różnych transportów i współdzielonej pamięci) oraz sock (standardowe gniazda TCP/IP).
Implementacja MPICH początkowo nie miała wsparcia infiniband (IB). Zostało ono dodane poprzez integrację z frameworkami OFI oraz UCX. Domyślnym środowiskiem uruchamiania procesów MPI (implementacja launchera mpiexec) jest Hydra (czasem dostępny jest alias mpiexec.hydra).
Najnowsza wersja MPICH to 4.1.2 wydana w czerwcu 2023. Przez jakiś czas biblioteka była oznaczana jako MPICH2, ale od wersji 3.0 stosowana jest już tylko nazwa MPICH. Główny numer wersji odpowiada oznaczeniu, że implementacja wspiera standard MPI-4.0. W ostatnim czasie MPICH jest dodatkowo rozwijany w ramach projektu Exascale Computing Project.
Więcej informacji¶
Open MPI¶
![]()
Open MPI (nie mylić z OpenMP), w skrócie OMPI, to implementacja standardu MPI, zbudowana według innych założeń niż MPICH. Jej historia również sięga początków MPI, gdyż powstała z połączenia kilku innych początkowych implementacji standardu. Posiada rozbudowane możliwości konfiguracji i pozwala na kontrolę zachowania biblioteki na poziomie różnych warstw.
Open MPI posiada swoje własne środowisko uruchomieniowe ORTE (Open Run-Time Environment) a launcher mpiexec posiada dodatkowy alias orterun. Stąd zestaw opcji mpiexec jest różny od tych dostępnych w MPICH (launcher hydra). Przyszła wersja OMPI (5.0) będzie korzystać z PRRTE, który zastąpi ORTE.
Struktura Open MPI bazuje na trzech warstwach (OMPI, ORTE oraz OPAL) oraz modułowej architekturze MCA (Modular Component Architecture)1. W jej ramach występują tzw. frameworki (frameworks), które odpowiadają za realizację konkretnych funkcjonalności. Dany framework może być zrealizowany poprzez kilka komponentów (components). Warto wyróżnić:
-
coll ─ odpowiada za operacje kolektywne
-
pml (point-to-point messaging layer) ─ odpowiada za komunikację bezpośrednią
- może być realizowana komponentami
ob1,cm, orazucx
- może być realizowana komponentami
-
btl (byte transport layer) ─ warstwa poziom niżej niż pml
- realizuje komunikację dla komponentu
ob1z pml - zawiera m.in. komponenty
ofi,sm,tcp
- realizuje komunikację dla komponentu
-
mtl (matching transport layer) ─ warstwa poziom niżej niż pml
- realizuje komunikację dla komponentu
cmz pml - zawiera m.in. komponenty
ofi,psm2(OmniPath)
- realizuje komunikację dla komponentu
-
io ─ odpowiada za operacje MPI I/O
- realizowana przez komponenty
romiolubompio
- realizowana przez komponenty

schemat modułowej struktury MCA w Open MPI [źródło]
Taka konstrukcja OMPI znajduje swoje odzwierciedlenie w możliwościach sterowania zachowaniem poszczególnych komponentów poprzez parametry MCA. OMPI posiada wsparcie dla InfiniBand (IB) m.in poprzez UCX (w frameworku PML) oraz OFI (w frameworku MTL).
Aktualna wersja Open MPI to 4.1.5, wydana w lutym 2023 r. W pełni wspiera standard MPI-3.1. Standard MPI-4.0 jest wdrażany do wersji rozwojowej 5.0. W ostatnim czasie Open MPI jest dodatkowo rozwijany w ramach projektu Exascale Computing Project (gdzie jest określany nazwą OMPI-X).
Więcej informacji¶
- strona Open MPI
- repozytorium
- dokumentacja (zbiór dokumentacji dla różnych wersji)
- obecna wersja (4.1.5) (zawiera tylko opis komend oraz API)
- FAQ (zawiera wiele informacji, o różnym poziomie aktualności)
- wersja rozwojowa (5.0) (nowa, czytelna dokumentacja dla przyszłej wersji – należy pamiętać że niektóre informacje mogą różnić się od tego jak działa obecna wersja stabilna)
- materiały
- "The ABCs of OpenMPI" (2020) seria czytelnie prezentuje strukturę Open MPI
MVAPICH¶
![]()
Implementacja powstała na podstawie biblioteki MPICH w 2001 roku. Jej celem było wdrożenie obsługi InfiniBand. Wspiera wiele transportów (InfiniBand, Omni-Path, Ethernet/iWARP, RoCE, Slingshot). Tak jak MPICH opiera się na tzw. urządzeniach i kanałach (przy czym korzysta ze starszego ch3).
Podstawowa implementacja oznaczana jest jako MVAPICH2. Opiera się ona na konkretnej wersji MPICH, a jej kod źródłowy jest publicznie dostępny. Posiada kilka odmian, wzbogaconych o dodatkowe funkcjonalności lub zoptymalizowanych pod konkretny sprzęt. Ich kod zwykle nie jest publicznie dostępny. Najważniejsze z nich to:
- MVAPICH2-GDR ─ wersja rozszerzona o wsparcie dla technologi CUDA > GPUDirect RDMA, służącej do bezpośredniej komunikacji między kartami GPU firmy NVIDIA;
- MVAPICH2-X ─ wersja rozszerzona o zaawansowane funkcjonalności, przewidziane do wydajnego korzystania z MPI w środowiskach exaskalowych; wspiera programowanie i łączenie ze sobą modeli MPI, OpenMP, oraz PGAS (np. UPC, OpenSHMEM;
- MVAPICH-Plus ─ wersja łącząca w sobie możliwości MVAPICH2-GDR oraz MVAPICH2-X.

schemat możliwości MVAPICH2-X [źródło]
Aktualna wersja MVAPICH2 to 2.3.7 wydana w lutym 2022. Jest ona oparta o MPICH w wersji 3.2.1 (m.in. zapewnia kompatybilność binarną z tą wersją). Posiada pełne wsparcie standardu MPI-3.1. Kolejne wersje MVAPICH starają się uaktualnić do nowszej wersji MPICH i zaadaptować jej funkcjonalności.
Więcej informacji¶
Pozostałe implementacje¶
Implementacje producentów¶
-
Intel MPI ─ Dystrybucja MPI dostarczana przez firmę Intel. Powstała na bazie MPICH. Cechuje się dużymi możliwościami konfiguracyjnymi. Dawniej jej zaletą było wspieranie kilku różnych transportów (DAPL, OFA) i możliwość ich przełączania na etapie uruchomienia programu. Obecnie opiera się o OFI i za pośrednictwem tego interfejsu umożliwia korzystanie z wielu transportów. Posiada opcję automatycznego tuningu, która pozwala na dobranie dla konkretnej aplikacji odpowiednich parametrów warstwy transportowej. Dostępna do pobrania jako osobny pakiet lub jako część Intel oneAPI HPC Toolkit.
Ostatnia wydana wersja to 2021.10.0 z lipca 2023 r. (numeracja nie jest zgodna z numerem toolkitu). Ta wersja wprowadziła osobne wrapperympiicx,mpiicpxorazmpiifxdla kompilatorów Intel opartych na LLVM (wcześniej wymagane było dodawanie opcji dompiccnp.mpicc -cc=icxdo użycia icx). Posiada pełne wsparcie standardu MPI-3.1. Kolejne wydawane wersje stopniowo wdrażają elementy standardu MPI-4.0.
-
HPE Cray MPI (dawniej Cray MPI) ─ Implementacja stosowana dla środowiska komputerów HPE Cray opartego o HPE Slingshot Interconnect (dostępnego np. w superkomputerze LUMI). Również bazuje na MPICH. Posiada wsparcie zarówno dla OFI (domyślnie) jak i UCX. Ostatnia wydana wersja to 23.05 z czerwca 2023 r.
Implementacje dla innych języków¶
Standard MPI określa interfejsy dla Fortran i C. Ten drugi oczywiście może być wykorzystany w programach C++. Dla niektórych innych języków istnieją biblioteki pośredniczące, które dostarczają swój własny interfejs (wzorowany na standardzie). Nie są to osobne implementacje – pod spodem wywołują one którąś z właściwych implementacji MPI. Takie powiązanie interfejsu biblioteki z innym językiem czasem określa się jako language binding.
- mpi4py ─ dojrzała implementacja MPI dla języka Python; w przeciwieństwie do standardowego API udostępnia wygodny interfejs obiektowy
- FastMPJ ─ MPI dla Java
- MVAPICH2-J ─ wersja biblioteki MVAPICH2 z interfejsem dla Java
- MPI.jl ─ MPI dla Julia
Kompatybilność binarna¶
Kompatybilność binarna bibliotek zachodzi wtedy gdy posiadają one taki sam interfejs binarny (ABI – application binary interface). Oznacza to, że z perspektywy niskopoziomowej wszystkie funkcje wywołuje się w ten sam sposób (odpowiednie argumenty są tego samego typu i przekazuje się je przez te same rejestry). Z perspektywy użytkowej pozwala to na możliwość podmiany biblioteki bez konieczności rekompilacji programu. Dokładniej mówiąc: program skompilowany z jedną biblioteką (poprzez linkowanie dynamiczne) może z powodzeniem zostać uruchomiony z inną biblioteką.
W przypadku implementacji MPI mogłoby się wydawać, że wszystkie powinny być kompatybilne. W teorii wszystkie mają ten sam interfejs (a więc te same nazwy funkcji i argumenty) a więc powinny być zgodne. Jednakże trzeba rozróżnić interfejs programistyczny od interfejsu binarnego. Zgodność interfejsu programistycznego ze standardem sprawia, że z powodzeniem można skompilować ten sam kod z różnymi implementacjami MPI. Jednakże na poziomie binarnym mogą występować nieznaczne różnice. W szczególności poszczególne struktury (typy danych) definiowane przez standard mogą być inaczej zaimplementowane. To zaś może prowadzić do nieścisłości na poziomie binarnym, które mogą prowadzić do bardzo poważnych (i trudnych do wychwycenia) błędów.
Najpoważniejsze różnice występują między MPICH oraz Open MPI. Dostępne są narzędzia, które pozwalają uruchomić ten sam program w obydwóch środowiskach. Pomiędzy implementacjami wywodzącymi się z MPICH bardzo często zachodzi kompatybilność binarna. Przykładowo MVAPICH2-2.3.7 bazuje na MPICH-3.2.1 i jest z tą wersją kompatybilny. Jakiś czas temu istniała inicjatywa utrzymywania kompatybilności ABI dla pochodnych MPICH. Należy jednak zwracać uwagę na numer wersji, gdyż w obrębie tej samej implementacji może dojść do zmiany ABI przy przejściu do nowszej wersji.
Eksperymentowanie z kompatybilnością
Uruchomienie programów skompilowanych z MPICH może powieść się pod Open MPI, ale trzeba być bardzo ostrożnym – wskazanie do którego momentu program binarny jest kompatybilny z obydwoma implementacjami jest trudne do ustalenia. Wskazane jest aby kompilować swój program pod każdą z tych implementacji osobno.
Narzędzia¶
- WI4MPI (Wrapper Interface For MPI) ─ Narzędzie pozwalające na uruchamianie tego samego programu zarówno w środowisku MPICH (oraz jego pochodnymi) jak i Open MPI. Za jego pośrednictwem można uruchomić program skompilowany z jedną implementacją w drugim środowisku (poprzez tzw. preload warstwy pośredniczącej). Możliwe jest również skompilowanie z warstwą pośrednią dostarczaną przez WI4MPI, która może zostać uruchomiona zarówno z jedną jak i drugą implementacją.
- MPItrampoline + MPIwrapper ─ Biblioteki pośredniczące do innych implementacji, mające na celu umożliwienie uruchamiania raz skompilowanego programu z wieloma implementacjami MPI. Program należy budować z biblioteką "MPItrampoline", która imituje implementację MPI a jednocześnie definiuje ABI (interfejs binarny). Tak skompilowany program może zostać uruchomiony z dowolną biblioteką MPI, poprzez "MPIwrapper" skompilowany dla tejże implementacji.
Linki¶
- strona MPI Forum
- dokumentacja
- materiały
- status wdrożenia standardu
- kursy uniwersyteckie
- wprowadzenie do MPI (LLNL) – krótka wersja dot. podstaw MPI
- cykl kursów dot. MPI (Cornell) – od podstaw do zaawansowanych tematów MPI
- szkolenia
- szkolenie z ANL (2019) – przejrzyste prezentacje dot. podstaw oraz zaawansowanych tematów
- kompleksowy kurs z HLRS – kompleksowy kurs dr. Rolfa Rabenseifnera, jednego z autorów standardu, pokrywa większość funkcjonalności oraz szczegółów, zaktualizowany o najnowsze funkcjonalności MPI-4.0
-
Przystępny opis architektury MCA (nowa dokumentacja) znajduje się w dokumentacji przyszłej wersji Open MPI (wersja rozwojowa 5.0). Należy mieć na uwadze, że struktura nowej wersji może odbiegać od obecnej stabilnej wersji (4.1.x). ↩