Model Roofline
Wprowadzenie¶
Model Roofline to model analizy wydajności służący do oceny wydajności aplikacji względem sprzętowych czynników limitujących, takich jak szybkość pamięci (tzw. memory bound) oraz możliwości obliczeniowe procesora/akceleratora (tzw. compute bound). Opiera się o pomiar wydajności obliczeń mierzonej zwykle we FLOPS-ach względem tzw. intensywności obliczeń (computational/arithmetic intensity).

wizualizacja modelu – maksymalna wydajność aplikacji (pogrubiona linia) jest ograniczona przez szybkość pamięci oraz możliwości obliczeniowe procesora [źródło]
Model może być stosowany do różnych konfiguracji sprzętowych, m.in.:
- dla pojedynczego rdzenia CPU,
- dla całego procesora (lub kilku procesorów w obrębie tej samej maszyny),
- dla akceleratora GPU.
Podstawowe pojęcia¶
Model jest oparty o następujące pojęcia. Ich znajomość jest konieczna do odpowiedniej interpretacji wyników.
- FLOPS (floating-point operations per second, także Flop/s) – jednostka miary wydajności obliczeń, którą możemy odnieść zarówno do wydajności konkretnego programu jak i do mocy obliczeniowej procesora. Oznacza średnią liczbę operacji zmiennoprzecinkowych wykonywanych w jednej sekundzie. Więcej szczegółów: wydajność obliczeń > FLOPS.
- Teoretyczna moc obliczeniowa (Peak FLOPS) – oznacza maksymalną liczbę FLOPS-ów jaką może uzyskać dany układ obliczeniowy. Więcej szczegółów: wydajność obliczeń > moc obliczeniowa.
- Przepustowość pamięci (bandwidth) – maksymalna szybkość z jaką procesor może odczytywać lub zapisywać dane z pamięci. Mierzona w GB/s. Więcej szczegółów: szybkość dostępu do danych.
- Intensywność obliczeń – nieco mniej znane pojęcie, kluczowe dla modelu Roofline; określa jak dużo operacji jest wykonywanych względem ilości danych pobieranych z pamięci. Szczegóły poniżej.
Intensywność obliczeń¶
Intensywność obliczeń dotyczy konkretnego programu lub jego fragmentu (np. danej pętli lub funkcji). Oznacza stosunek poniższych wartości:
- ilość operacji zmiennoprzecinkowych (Flop, także FLOP lub flop),
- ilość danych (w bajtach), które muszą zostać przetransferowana z/do pamięci, w celu wykonania danych obliczeń.
Inaczej mówiąc, jest to średnia liczba operacji wykonywanych w przeliczeniu na 1 bajt danych. Wartość intensywności wyraża się jako Flop/B.

liczba operacji i rozmiar danych dla prostego działania [źródło]
To samo pojęcie – różne określenia
Różne źródła nt. Roofline używają różnych nazw na to pojęcie. Najczęstsze to arithmetic intensity oraz computational intensity. Czasem można spotkać się z operational intensity. Jak więc widać, oprócz wybranej przez nas "intensywności obliczeń", możemy również mówić o "intensywności arytmetycznej" lub "natężeniu operacji".
Interpretacja wskaźnika:
- niska intensywność – oznacza, że program w niewielkim stopniu przetwarza pobierane dane i generuje dużo dostępów do pamięci w stosunku do ilości obliczeń;
- wysoka intensywność – oznacza, że program wykonuje wiele przekształceń na tych samych danych i stosunkowo rzadko odwołuje się do pamięci.
Przykład wyznaczania intensywności
Rozważmy poniższą, prostą pętlę:
// double a, X[], Y[], Z[];
for(i=0; i<N; i++){
Z[i] = X[i] + a*Y[i];
}
Pojedyncza iteracja:
- wykonuje 2 Flopy
- pierwszą operacją jest mnożenie
a*Y[i], - drugą dodawanie
X[i]do wyniku powyższego mnożenia;
- pierwszą operacją jest mnożenie
- generuje 3 dostępy do pamięci, łączny transfer to 24 bajty
- zmienne są typu
doubleczyli każda jest rozmiaru 8 bajtów, - występują dwa odczyty (
X[i]orazY[i]) oraz jeden zapis (Z[i]).
- zmienne są typu
Otrzymujemy więc intensywność obliczeń
Flop/B. Gdyby zmienny były typu float (4 bajty), wtedy intensywność wyniosłaby
Flop/B.
Doprecyzowując, ponieważ w każdej iteracji jest wykonywane to samo działanie, intensywność obliczeń dla całej pętli będzie równa intensywności dla pojedynczego kroku. Przy takim założeniu pomijamy odczyt zmiennej a, która jest ładowana tylko jeden raz – przy dużych N jej udział w intensywności jest zaniedbywalny.
Przykład – większa intensywność
W tym przykładzie pętla wykonuje kilka operacji na zmiennych.
// double X[], Y[], Z[];
for(i=0; i<N; i++){
x = X[i];
y = Y[i];
Z[i] = x*x + x*y + y*y - y;
}
Skupiamy się na pojedynczej iteracji. Wykonywane operacje zmiennoprzecinkowe to 3 mnożenia (x*x, x*y, y*y) oraz 2 dodawania i 1 odejmowanie wedle schematu: (dodano nawiasy dla oznaczenia działań). Daje to 6 Flopów.
Ilość ładowanych danych nie zmienia się z powodu przypisania ich do nowych zmiennych x i y (trafią one do rejestrów, więc nie wymagają ładowania podczas każdej operacji). Mamy więc, tak jak w poprzednim przykładzie, 2 odczyty i 1 zapis, każdy po 8 bajtów, czyli 24 bajty.
W takim wypadku intensywność obliczeń wynosi Flop/B.
Przedstawione przykłady obrazują, że do zwiększenia intensywności obliczeń konieczne jest wykonywanie większej liczby operacji na raz załadowanych danych.
Lokalność danych
Można powiedzieć, że intensywność obliczeń to miara lokalności danych, czyli stopień reużywalności w programie tych samych danych.
W powyższych obliczeniach nie został uwzględniony mechanizm pamięci podręcznej. Dokładniejsze omówienie znajduje się w sekcji wpływ pamięci cache na intensywność obliczeń.
Szczegóły¶
Zasadniczym celem modelu Roofline jest pomoc w odpowiedzi na pytanie: czy dany program efektywnie korzysta z możliwości sprzętowych?
Aby to osiągnąć, moc obliczeniowa komputera jest modelowana nie tylko poprzez jej maksymalną teoretyczną wartość (patrz wydajność obliczeń > moc obliczeniowa), ale również przez dodatkowe czynniki. W zależności od stopnia dokładności, można wyróżnić dwa podejścia:
- podstawowy model – skupia się na maksymalnej wydajności procesora oraz przepustowości pamięci RAM;
- rozszerzony model – uwzględnia również różne rodzaje operacji jakie może wykonywać procesor oraz bierze pod uwagę działanie pamięci podręcznej (cache).
W oparciu o model przeprowadzana jest ocena wydajności aplikacji. Na jej podstawie można wyciągnąć wnioski nt. potencjalnych sposobów optymalizacji wydajności.
Uwaga
Dla uproszczenia, w tekście piszemy "procesor". Należy jednak pamiętać, że model ma zastosowanie do różnych jednostek obliczeniowych: zarówno procesorów (CPU) jak i akceleratorów (GPU). Możemy go odnieść do pojedynczego rdzenia jak i do całego procesora.
Podstawowy model¶
Podstawowe podejście (czasem nazywane "naive roofline model") w prosty sposób oddaje główną ideę modelu. Dla danego komputera, maksymalna wydajność jest ograniczona przez dwa czynniki:
- wydajność procesora (Peak FLOPS),
- przepustowość pamięci RAM (bandwidth).
Model Roofline wprowadza kluczową jednostkę – intensywność obliczeń – względem której należy interpretować wydajność. Takie podejście pozwala zwizualizować, które z tych dwóch ograniczeń dominuje w którym zakresie. Charakterystyczny kształt tego wykresu przypomina dach, do czego nawiązuje nazwa modelu.

podstawowy wykres dla modelu Roofline [źródło]
Opis wykresu
Powyższy wykres przedstawia jaka jest możliwa do uzyskania wydajność (oś pionowa) w zależności od intensywności obliczeń (oś pozioma). Zwykle na obydwu osiach stosuje się skalę logarytmiczną (log-log scale).
-
Pozioma prosta (różowa) to ograniczenie wynikające z wydajności procesora. Maksymalna liczba FLOPS-ów odcina możliwą do uzyskania wydajność od nieosiągalnej za względu na prędkość obliczeń.
-
Prosta pochyła (niebieska) jest zadana przez przepustowość pamięci. Dokładniej mówiąc, jest ona wyznaczona jako x , gdzie – intensywność obliczeń (Flop/B), – przepustowość (GB/s). Odcina ona wydajność osiągalną ze względu na dostęp do pamięci.
-
Pogrubiona łamana (fioletowa) modeluje maksymalną moc obliczeniową – jest to minimum z obydwóch wartości. Każda aplikacja może uzyskać wydajność tylko w oznaczonym obszarze pod tą łamaną.
Przesłanie modelu Roofline
Wydajność poszczególnych funkcji należy oceniać w odniesieniu do intensywności obliczeń!
Maksymalna wydajność czasem jest określana jako "speed of light". Warto zauważyć, że jest ona niezależna od aplikacji, tylko charakteryzuje dany komputer i układ obliczeniowy.
Interpretacja wykresu¶
Interpretacja maksymalnej wydajności wynikającej z modelu jest dość intuicyjna. Zakładamy warunki idealne, w których:
- obliczenia są wykonywane najszybciej jak procesor potrafi,
- dane są dostarczane w sposób ciągły, z prędkością równą przepustowości pamięci,
- obliczenia nie wpływają na dostępy do pamięci i na odwrót (czyli zakładamy perfekcyjne zrównoleglenie tych operacji).

dane a obliczenia [źródło]
Przy niskiej intensywności obliczeń, procesor ma do wykonania mało operacji względem danych pobieranych z pamięci. W związku z tym, zdąży wykonać obliczenia zanim zostanie dostarczona kolejna paczka danych. W efekcie procesor czeka na dostarczenie nowych danych i nie wykonuje w tym czasie kolejnych operacji – wydajność jest ograniczona przez przepustowość (memory/bandwidth bound).
Im większa intensywność, tym więcej pracy procesor wykonuje żeby przetworzyć daną paczkę danych. W konsekwencji, wraz ze wzrostem intensywności, jego czas bezczynności ulega zmniejszeniu. Po przekroczeniu pewnej wartości, procesor potrzebuje na tyle dużo czasu na przetworzenie danych, że szybkość pamięci przestaje być czynnikiem ograniczającym – wydajność jest ograniczona przez moc obliczeniową (compute bound).
Analogia – praca fabryki
Wyobraźmy sobie małą fabrykę, w której na każdym stanowisku znajduje się maszyna (CPU) do obrabiania pewnego materiału (dane). Pamięć RAM w tej metaforze to magazyn, z którego dostarczany jest materiał do stanowisk pracy. Przepustowość to prędkość wózka widłowego, który go przewozi.
Analiza przy pomocy modelu Roofline jest podobna do oceny wydajności pracy tej fabryki. Jeżeli maszyna pracuje tak szybko, że cały materiał zostanie przerobiony zanim wózek wykona jeden obrót, to czynnikiem limitującym jest prędkość dostarczania materiału. Dopiero gdy pracy jest odpowiednio dużo, wózek przywiezie kolejną paczkę materiału szybciej niż maszyna zakończy obrabianie. W takim wypadku czynnikiem limitującym jest tempo pracy maszyny.
Model empiryczny¶
Dla danego komputera, wykres Roofline obrazujący jego wydajność można wykonać na podstawie teoretycznych wartości, wyznaczając je w oparciu o specyfikację sprzętu. Jednakże dużo bardziej użyteczne jest wykonanie benchmarków, które w sposób rzeczywisty zmierzą jaka wydajność jest możliwa do uzyskania. Przykładem może być STREAM – klasyczny benchmark służący do pomiaru przepustowości pamięci.
Wykres otrzymany w ten sposób to model empiryczny. Wiele aplikacji do analizy wydajności (patrz narzędzia) automatycznie dokonuje pomiaru osiągalnej wydajności. Dzięki temu, maksymalne wartości na takim wykresie to wydajność, którą faktycznie można uzyskać.
Przepustowość pamięci a wielordzeniowość
Należy pamiętać, że przepustowość pamięci jest zależna od tego ile użyjemy rdzeni oraz od sposobu przypięcia procesów/wątków (tj. od tego czy procesy są rozproszone po socketach oraz węzłach NUMA czy znajdują się w obrębie tej samej jednostki). Dla zobrazowania, zobacz:
Ocena wydajności aplikacji¶
Analiza aplikacji w oparciu o model Roofline polega na ustaleniu intensywności obliczeń oraz zmierzeniu uzyskanej liczby FLOPS-ów. Zwykle w tym celu wykorzystuje się odpowiednie narzędzia. Taki pomiar ma największy sens względem małych fragmentów kodu źródłowego (np. funkcji/kerneli lub pętli). Uzyskany wynik umieszcza się jako punkt na wykresie.


W pewnym uproszczeniu, interpretacja wydajności jest następująca:
- wynik blisko górnego ograniczenia oznacza dobrą wydajność,
- w zależności poniżej której granicy znajduje się wynik, aplikację można uznać za memory-bound (niebieski obszar) lub compute-bound (czerwony obszar),
- za granicę przyjmuje się uzyskanie 50% maks. wydajności (należy pamiętać, że wykres jest w skali logarytmicznej);
- wynik poniżej oznacza nieefektywność wykorzystania zasobów,
- im niżej znajduje się wynik, tym większy potencjał na optymalizację.
Obserwacja – identyfikacja funkcji do optymalizacji
Model Roofline dostarcza głębszego spojrzenia na wydajność poszczególnych funkcji niż tylko porównywanie ze sobą osiągniętej wydajności. Warto zauważyć, że mogą wystąpić:
- funkcje które mają niską wydajność, ale efektywnie wykorzystują zasoby sprzętowe (ich optymalizacja nie przyniesie zbytniej poprawy),
- odwrotnie, funkcje o wysokiej wydajności, które jednak nie są zbyt efektywne i mogą zostać zoptymalizowane.

Oczywiście nie można zapomnieć, że w pierwszej kolejności należy optymalizować te funkcje, których wykonanie zajmuje najwięcej czasu. Niektóre narzędzia nanoszą na wykres informację o czasie trwania funkcji poprzez rozmiar punktu lub jego kolor.
Ogólna strategia optymalizacji jest następująca:
- przybliżenie w kierunku "sufitu" – poprawa wydajności obliczeń poprzez zwiększenie wykorzystania możliwości procesora (np. wektoryzacja, większe obłożenie jednostek wykonawczych);
- podniesienie "na skos" – zwiększenie intensywności obliczeń, tj. poprawa sposobu dostępu do pamięci (np. unikanie pobierania tych samych danych ponownie, lepsze wykorzystanie pamięci cache).

orientacyjne sposoby optymalizacji wydajności [źródło]
Porada
Należy pamiętać, że może być wiele przyczyn niskiej efektywności wykorzystania zasobów. Do lepszego wyciągania wniosków należy skorzystać z rozszerzonego modelu (opis poniżej).
Przykład zastosowania modelu
Poniżej został przedstawiony przykładowy proces rozwoju programu z wykorzystaniem modelu Roofline do analizy czynników limitujących wydajność.

- Punkt startowy (czerwona kropka) – Program uzyskał wydajność znacznie poniżej maksymalnej dostępnej wydajności, w obszarze memory-bound. Niska wydajność oznacza potencjalną możliwość optymalizacji.
- Krok 1 – Przepisano kod z języka Python na Fortran. W efekcie wydajność stała się bezpośrednio ograniczona przez przepustowość pamięci.
- Krok 2 i 3 – Zmniejszono liczbę dostępów do pamięci, co pozwoliło zwiększyć intensywność obliczeń. Program stał się compute-bound, jednakże nadal nie jest on maksymalnie wydajny.
- Krok 4 – Wykorzystano instrukcje wektorowe i osiągnięto maksymalną możliwą wydajność.
Rozszerzony model¶
Przedstawiony powyżej podstawowy model pozwala zrozumieć ideę modelu Roofline. Jednakże aby uzyskać kompletniejszy obraz efektywności wykorzystania możliwości obliczeniowych danego komputera, należy uwzględnić:
- ograniczenia wynikające ze specyfiki obliczeń np. braku wykorzystania wektoryzacji lub instrukcji różnego rodzaju (omówione poniżej),
- wykorzystanie pamięci podręcznej procesora (patrz hierarchia pamięci).
Ograniczenia wydajności – rodzaj instrukcji¶
Nawiązując do tego jak jest wyznaczana moc obliczeniowa, kluczową rolę odgrywa rodzaj instrukcji oraz to czy jest możliwa wektoryzacja. W sytuacji gdy dany program np. nie korzysta z FMA, z góry wiadomo, że maksymalna wydajność jaką może uzyskać jest mniejsza. Model Roofline pozwala zwizualizować to w dogodny sposób. Dla każdego rodzaju obliczeń można dodać kolejny "sufit" – poziomą linię oddzielającą osiągalną wydajność od nieosiągalnej.

wykres roofline uwzględniający rodzaj operacji oraz wektoryzację [źródło]
Omówienie wykresu
Maksymalna liczba FLOPS-ów jest zależna od rodzaju wykonywanych operacji. Na powyższym mamy 54 GFLOPS, 27 GFLOPS, 7 GFLOPS odpowiednio dla:
- DP Vector FMA – zwektoryzowane wykonanie FMA dla liczb podwójnej precyzji,
- DP Vector Add – zwektoryzowane dodawanie liczb podwójnej precyzji,
- Scalar Add – standardowe dodawanie liczb zmiennoprzecinkowych (brak wektoryzacji).
Zauważmy, że uzyskana wydajność odpowiada oczekiwaniom. Przyjmując, że rejestry wektorowe tego systemu mają rozmiar 256 bitów, pojedyncza instrukcja wektorowa Vector Add wykona 4 operacje w tym samym czasie, w którym wykonuje się jedna instrukcja Scalar Add. W efekcie jej wydajność jest ok. 4x wyższa. Z kolei FMA to instrukcja, która w jednym kroku wykonuje dodawanie i mnożenie. W tym samym czasie jest więc realizowane dwa razy więcej Flopów.
Kropki o różnych kolorach oznaczają wydajność różnych funkcji. W tym wypadku wszystkie wyglądają na ograniczone przez pamięć.
Zauważmy również, że biorąc pod uwagę instrukcje wektorowe lub tensorowe oraz mniejszą precyzje obliczeń niż FP64, możemy z kolei dostać ograniczenia, które będą powyżej klasycznie wyznaczonej maksymalnej wydajności.

wykres roofline dla obliczeń zwykłych i tensorowych (WMMA) dla GPU [źródło]
Patrząc na powyższe, łatwo sobie wyobrazić dodawanie kolejnych linii ograniczających. Idąc dalej, model Roofline zwykle jest stosowany w odniesieniu do operacji zmiennoprzecinkowych, ale przez analogię, można go przenieść do obliczeń całkowitoliczbowych.
Ograniczenia wydajności – miks instrukcji¶
Standardowo maksymalna wydajność odnosi się do operacji zmiennoprzecinkowych. W sytuacji gdy dana funkcja/kernel oprócz Flopów wykonuje również wiele innych operacji, wtedy maksymalna wydajność może być ograniczona.
Przykładowo, jeśli procesor jest w stanie jednocześnie pobierać/wykonywać 4 instrukcje i posiada 2 FPU (jednostki wykonawcze do realizacji operacji zmiennoprzecinkowych), wtedy maksymalna wydajność FLOPS jest osiągalna tylko, jeśli przynajmniej połowa instrukcji to Flopy. Przy mniejszych proporcjach, górne ograniczenie wydajności jest odpowiednio niższe (wystąpi wtedy tzw. FPU starvation).

przykładowe ograniczenia wydajności w zależności od proporcji operacji Flop [źródło]
Podobnie, nawet jeśli większość operacji to Flopy, ale mamy do czynienia z mieszanką różnych typów operacji (np. część jest wektoryzowana a część nie, operacje są w różnych precyzjach) maksymalna wydajność będzie ograniczona. W takim wypadku "sufit" wystąpi gdzieś pomiędzy górnymi ograniczeniami dla różnych rodzajów operacji.

maksymalna wydajność dla różnych operacji dla GPU [źródło]
Hierarchia pamięci¶
Podstawowy model odwołuje się do przepustowości pamięci, mając na myśli przepustowość pamięci RAM (DRAM). Tymczasem układy obliczeniowe posiadają pamięć podręczną (cache), która ma dużo większą przepustowość niż pamięć główna. Typowy procesor posiada trzy poziomy cache'a (L1, L2, L3), z których pierwszy jest najbliższy procesorowi.

hierarchia pamięci – im bliżej procesora tym większa przepustowość [źródło]
Podobnie jak w przypadku ograniczeń dot. wydajności obliczeń, uwzględnienie pamięci podręcznej polega na tym, że na wykresie umieszcza się dodatkowe skośne linie, powyżej przepustowości RAM. Jednakże aby z nich skorzystać trzeba doprecyzować sposób wyznaczania intensywności obliczeń.

model Roofline uwzględniający hierarchię pamięci
NUMA w modelu Roofline
W modelu można również uwzględnić efekt jaki wywołuje NUMA. Niższa wydajność dostępu rdzenia CPU do pamięci z nie swojego węzła NUMA będzie modelowana poprzez sufit znajdujący się poniżej przepustowości pamięci RAM.


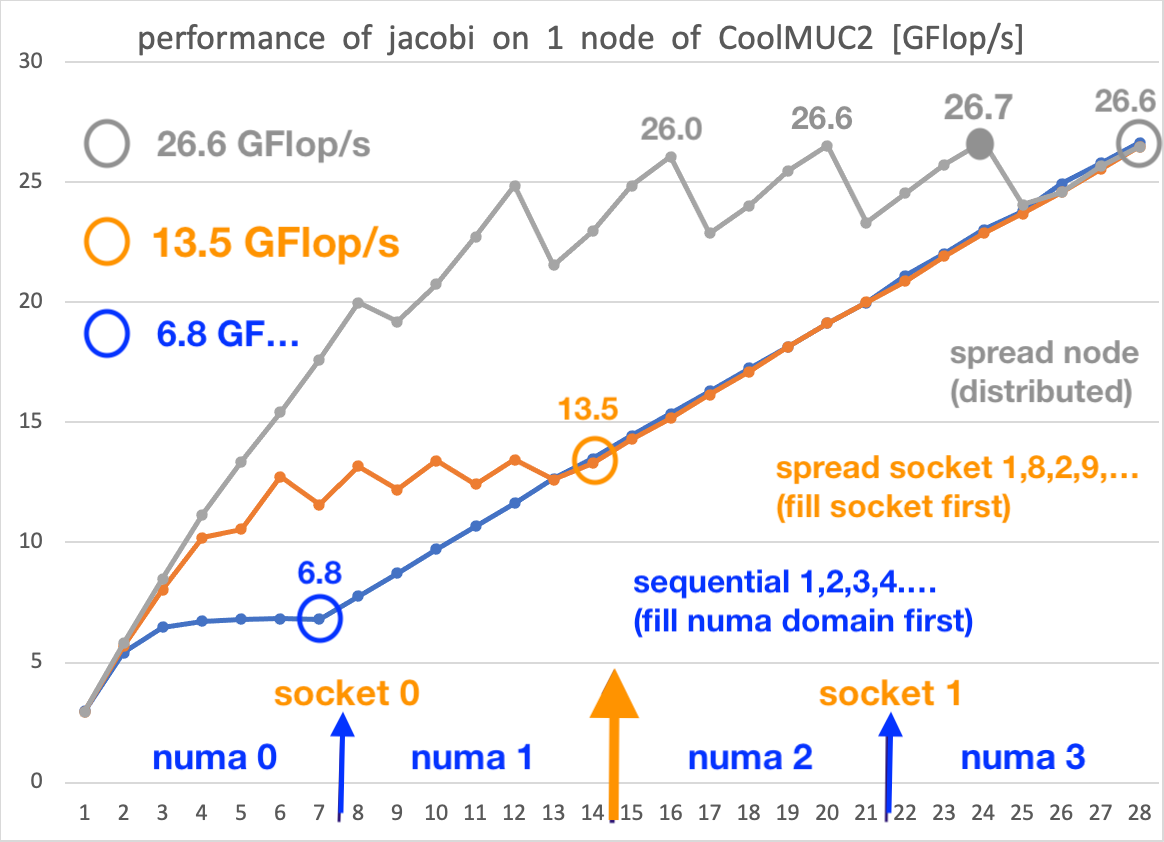{kind=link}
Wpływ pamięci cache na intensywność obliczeń¶
Kluczowa obserwacja polega na tym, że dla danych obliczeń, ze względu na to jak działa cache, ilość danych przesyłanych na każdym poziomie pamięci jest różna. Mamy tu na myśli dane przesyłane np. między pamięcią główną a L3 albo L3 a L2 itd. W efekcie, w zależności od tego względem którego poziomu hierarchii pamięci mierzymy transfer danych, otrzymujemy różne wartości intensywności obliczeń. To z kolei wpływa na maksymalną wydajność, jaka może zostać uzyskana.

maksymalna wydajność uwzględniająca różne intensywności (oznaczone tutaj przez AI) [źródło]
Ustalając rozmiar transferu danych, pod uwagę należy wziąć następujące mechanizmy:
- dane między RAM-em a cache'em oraz między niższymi poziomami cache'a są pobierane paczkami o ustalonym rozmiarze (pojedyncza paczka to tzw. linia cache'a);
- jeśli dane znajdują się w niższym poziomie, nie generuje to dostępu do wyższego poziomu cache'a oraz pamięci RAM;
- czasem dane są pobierane z wyprzedzeniem (prefetch).
Przykład
Rozważmy pierwszy przykład z sekcji intensywność obliczeń:
// double a, X[], Y[], Z[];
for(i=0; i<N; i++){
Z[i] = X[i] + a*Y[i];
}
Do wyznaczenia intensywności obliczeń ( Flop/B) przyjęliśmy, że pojedyncza iteracja:
- wykonuje 2 Flopy,
- generuje transfer 24 bajty.
Mierząc transfer danych względem pamięci RAM jest to pewne uproszczenie, które dla odpowiednio dobranych lub dużych N jest prawidłowe. Uwzględniając działanie cache'a, transfer danych wygląda następująco:
- przyjmijmy, że adresy początków tablic
X[],Y[],Z[]są zgodne z początkiem linii cache'a; - pierwsze dostępy do tablic (
X[0],Y[0]orazZ[0]) spowodują pobranie odpowiednich linii z pamięci RAM do cache; - kolejne odwołania, aż do końca linii cache'a, nie wygenerują transferu danych z RAM;
- wraz z początkiem kolejnych linii, efekt ten będzie się powtarzał.
W rezultacie:
- intensywność obliczeń dla pierwszej iteracji jest bardzo mała (2 Flopy vs rozmiar trzech linii cache'a);
- wraz z kolejnymi iteracjami intensywność obliczeń tej pętli zmierza do wyznaczonej uprzednio wartości Flop/B, osiągając ją w momencie pełnego przetworzenia całej linii cache'a;
- po wejściu do kolejnej linii, intensywność znowu spada (im dalsza linia ten spadek jest mniejszy), ale wraz z jej końcem wraca do ustalonej wartości.
Podsumowując, z perspektywy obliczeń, mechanizmy dot. pamięci cache mogą sprawić, że część danych zostanie pobrana z RAM niepotrzebnie. Taka sytuacja powoduje obniżenie intensywności obliczeń. Im mniejsze N, tym narzut na niepotrzebnie pobrane dane może być bardziej odczuwalny.
Na koniec zauważmy, że mierząc transfer danych względem pamięci L1 (między procesorem a L1) wartość Flop/B jest poprawna, niezależnie od ilości iteracji.
Różne warianty modelu¶
Jak stwierdziliśmy powyżej, dla każdego poziomu pamięci inna jest jej przepustowość oraz dane obliczenia generują inną intensywność. Mając to na uwadze, widać że analizę typu Roofline można zastosować do każdego z tych poziomów z osobna. Jest to o tyle istotne, że maksymalna wydajność może być ograniczona właśnie z powodu przepustowości pamięci cache.

przykład ograniczenia wydajności przez przepustowość pamięci L2 [źródło]
Obserwacja
Szczególnie użyteczna jest obserwacja transferu danych między CPU a L1. Jest to liczba danych, które faktycznie pobiera i zapisuje procesor – oddaje intensywność obliczeń z algorytmicznego punktu widzenia. Wartość ta jest niezależna od efektów cache'owania danych.

wizualizacja różnych możliwości pomiaru transferu danych – wariant cache-aware vs podstawowy model [źródło]
Istnieje kilka podejść do tego w jaki sposób odzwierciedlać hierarchię pamięci w modelu Roofline. Przekładają się one na różne warianty modelu:
- DRAM Roofline,
- podstawowy model, w którym cache nie jest uwzględniony,
- intensywność może się zmieniać w zależności od rozmiaru problemu (ze względu na opisane wcześniej efekty dot. cache'owania);
- Hierarchical Roofline (lub Memory-Level Roofline),
- polega na wyznaczaniu intensywności obliczeń osobno dla każdego poziomu pamięci,
- dana funkcja jest reprezentowana przez kilka punktów na wykresie;
- Cache-Aware Roofline (CARM),
- polega na wyznaczeniu jednej intensywności obliczeń, mierzonej względem L1 (dokładniej, ruch danych między procesorem a całą hierarchią pamięci),
- tak zmierzona intensywność jest niezależna od rozmiaru problemu.

przykład analizy dla kilku funkcji w modelu hierarchicznym [źródło]
Interpretacja wyników w Hierarchical Roofline
Dla modelu hierarchicznego, punkty dla różnych poziomów pamięci są na tej samej wysokości oznaczającej uzyskaną wydajność danej funkcji. Istotna tutaj jest odległość między intensywnościami obliczeniowymi dla różnych poziomów. Duże oddalenie oznacza, że z perspektywy wyższego poziomu dane są wielokrotnie wykorzystywane.

Interpretacja wyników w Cache-Aware Roofline
Dla modelu Cache-Aware możemy oceniać położenie wydajności względem sufitów wynikających z przepustowości różnych rodzajów pamięci. Przykładowo, im bardziej wydajność znajduje się ponad sufitem DRAM, tym lepsze wykorzystanie cache'a (obliczenia są bardziej lokalne).

Porównanie modelu Hierarchical z Cache-Aware

Podsumowanie¶
Model Roofline pozwala w intuicyjny sposób wizualizować możliwości obliczeniowe komputera oraz wydajność aplikacji. Główne elementy to:
- wykres maksymalnej możliwej do osiągnięcia wydajności,
- wyznaczony na podstawie przepustowości i wydajności procesora,
- charakteryzuje konkretny komputer i układ obliczeniowy;
- intensywność obliczeń,
- kluczowy czynnik, względem którego oceniamy wykorzystanie zasobów,
- charakteryzuje dany program/funkcję,
- zdeterminowana w największym stopniu przez wybrany algorytm oraz sposób jego implementacji,
- ze względu na sposób działania cache'y, szczegóły działania sprzętu również wpływają na jej wyznaczenie;
- pomiar wydajności aplikacji.
W oparciu o maksymalną wydajność oraz intensywność obliczeń dokonuje się interpretacji wydajności danej aplikacji/funkcji. Zbyt mała intensywność może oznaczać, że czynnikiem limitującym jest przepustowość pamięci. Im bardziej szczegółowy wykres – uwzględniający różne rodzaje operacji oraz działanie pamięci cache – tym łatwiej wyciągnąć poprawne wnioski.
Narzędzia¶
Istnieje wiele narzędzi służących do badania wydajności aplikacji. Niektóre spośród nich pozwalają na automatyczne przeprowadzenie analizy Roofline – empiryczne wyznaczenie osiągalnej wydajności oraz pomiar wydajności i intensywności obliczeń wskazanej aplikacji. Narzędzia z interfejsem graficznym w wygodny sposób wizualizują zebrane wyniki.
Szczegóły pomiarów
Różne narzędzia mogą wspierać różne warianty modelu w stosunku do modelowania pamięci cache. Warto sprawdzić który wariant jest używany przez dane narzędzie.
Również wartości potrzebne do wykresu Roofline mogą być wyznaczane w inny sposób (np. wykorzystując liczniki sprzętowe do mierzenia innych zdarzeń). Różnice mogą wystąpić szczególnie, gdy mamy do czynienia z procesorami różnych producentów. Jeśli więc potrzebna jest wiedza, co dokładnie wizualizuje dane narzędzie, należy poszukać informacji na ten temat w odpowiedniej dokumentacji.
Narzędzia dostarczane przez producentów procesorów:
-
AMD Omniperf – Narzędzie do profilowania kerneli wykonywanych na kartach GPU AMD z serii MI100/200/300. Analizę Roofline można sporządzić jako samodzielną analizę (patrz Standalone Roofline) bądź jako część innej (patrz Analysis). Obecnie jest ona dostępna tylko dla kart MI200 i wybranych systemów operacyjnych.1.
-
Intel Advisor – Służy do analizy kodu i poprawy jego wydajności, np. wskazuje miejsca, które mogą zyskać na zrównolegleniu czy wektoryzacji. Przeznaczony dla CPU i GPU firmy Intel. Posiada rozbudowane wsparcie dla modelu Roofline, który funkcjonuje w nim jako jeden ze sposobów badania ograniczeń wydajności (patrz Identify Performance Bottlenecks Using CPU Roofline oraz Roofline Resources).
-
NVIDIA Nsight Compute – Narzędzie do analizy wydajności aplikacji korzystających z GPU NVIDIA. Służy do szczegółowego badania poszczególnych kerneli, m.in. przy użyciu Roofline (patrz Kernel Profiling Guide). Posiada dodatkową wizualizację wykorzystania pamięci (patrz Memory Chart).
Pozostałe:
-
LIKWID – Zestaw narzędzi do analizy wydajności. Przy ich użyciu jest możliwe wykonanie analizy Roofline – LIKWID zbiera odpowiednie dane, z których można samodzielnie wygenerować wykres (patrz Tutorial: Empirical Roofline Model). Współpracuje z procesorami Intel, AMD, ARM oraz kartami graficznymi AMD i NVIDIA.
-
Empirical Roofline Tool (ERT) – Służy do empirycznego wyznaczenia wykresu Roofline dla danej maszyny (tj. osiągalnej wydajności). Nie pozwala na pomiar wydajności aplikacji. Do wizualizacji wyników z ERT służy Roofline Visualizer. Oba narzędzia są dostępne razem jako CS Roofline Toolkit. Są to wczesne narzędzia, obecnie nierozwijane (ostatnia aktualizacja w 2020 roku).
-
Kerncraft – Narzędzie nieco innego typu. Służy do analizy pętli i kerneli oraz modelowania ich wydajności, m.in. na podstawie statycznej analizy kodu źródłowego. Wspiera kilka modeli, w tym Roofline.
Linki¶
- omówienie modelu
- materiały
- materiały LBNL – zbiór materiałów grupy badawczej z Lawrence Berkeley National Laboratory, specjalizującej się w modelu Roofline (sekcja publikacje zawiera zarówno artykułu naukowe jak i prezentacje)
- 7-point stencil benchmark – przykładowy kod, na którym można wykonać analizę wydajności
- skrypt dla gnuplot – prosty skrypt do samodzielnego generowania wykresu
- prezentacje
- ECP23 – Introduction to the Roofline Model – rozbudowana prezentacja twórcy modelu Roofline, Samuela Williamsa2
- ECP23 – Roofline dla AMD, INTEL, NVIDIA – zastosowanie modelu dla różnych architektur
- "Simple" performance modeling: The Roofline Model (FAU) 3
- szkolenia
- ECP23 – Performance Tuning with the Roofline Model on GPUs and CPUs – nagranie do materiałów z ECP23 (wprowadzenie + zastosowania)
- Using the Roofline Model and Intel Advisor (2017) – nagranie oraz slajdy4
-
Wsparcie dla MI300 jest w trakcie rozwoju (patrz Issue #285 · ROCm/omniperf · GitHub). ↩
-
Istnieje wiele podobnych do siebie prezentacji Samuela Williamsa nt. Roofline. Jeden z wcześniejszych wariantów, zawierający trochę innych treści: SC18 – Introduction to the Roofline Model (2018). ↩
-
Nieco nowsza wersja dostępna jest w ramach kursu Node-Level Performance Engineering @HLRS. ↩
-
Slajd 8 w tej prezentacji zawiera błąd dot. wartości intensywności obliczeń: zamiast "AI = 0.166 flops per byte" powinno być 0.083. Późniejsze wersje tej prezentacji zawierają poprawną wartość. ↩